The Unseen Legacy of Ian Goodfellow’s 2014 Breakthrough in AI Image Generation
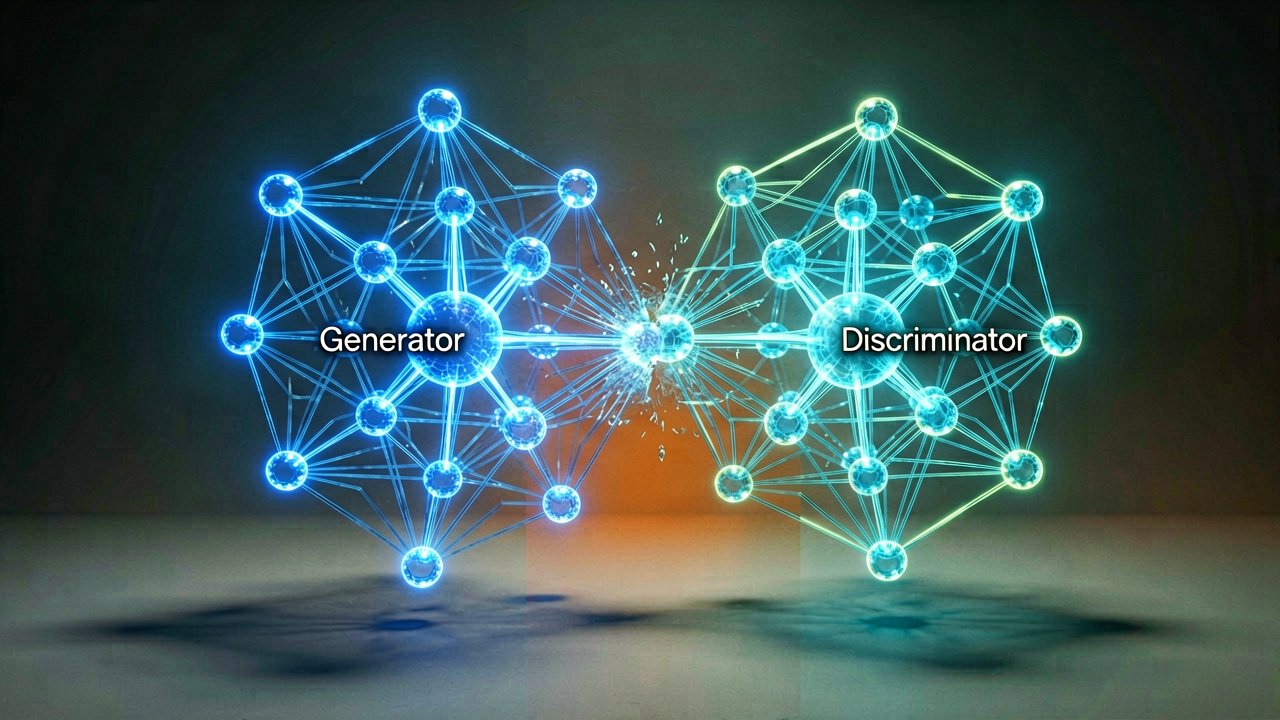
In 2014, a seminal paper published via arXiv fundamentally altered the trajectory of artificial intelligence. Ian Goodfellow and his co-authors introduced Generative Adversarial Networks (GANs), an architecture utilizing two competing neural networks—a generator and a discriminator—locked in a zero-sum, minimax game. By bypassing the computational reliance on Markov chains, this machine learning framework proved that deep neural networks could synthesize highly realistic data from random noise. The resulting methodology laid the conceptual and architectural foundation for the modern consumer-facing tools that dictate the creative technology sector today.
While newer frameworks like latent diffusion models have captured widespread consumer attention, the strategic footprint of the original adversarial framework remains massive. Market tracking data from Market.us shows that GANs still command a 37.4% technology usage share within the global AI-powered image generation tool market. This enduring presence reflects the unique computational efficiencies built into Goodfellow’s initial framework. Unlike iterative diffusion techniques that require multiple denoising passes, the direct feed-forward generation native to GANs offers rapid inference speeds. This makes them indispensable for real-time edge computing, video synthesis, and low-latency digital media workflows.
The enterprise monetization of these technologies has evolved from academic curiosities into a core economic driver for the media and entertainment sectors. According to regional insights from Grand View Research , North America captured a commanding 37.5% revenue share of the AI image generator market in 2023, propelled by mature e-commerce infrastructure, gaming hubs, and advertising agencies. Software-driven customization platforms lead this enterprise push, enabling automated asset creation and real-time interactive photo editing that directly traces its roots to early adversarial optimization research.
The Architecture of Competition: How Adversarial Frameworks Redefined Machine Learning
Goodfellow’s breakthrough shifted the generative paradigm by transforming a complex probability estimation problem into a structural competition. The generator network is tasked with mapping random latent variables to synthetic data points, while the discriminator evaluates whether the sample originates from the true training distribution or the synthetic pipeline. This continuous loop forces both networks to optimize simultaneously via backpropagation. By framing generation as a classification problem for the discriminator, the system learns highly intricate data distributions without requiring explicit density formulas, a distinct advantage noted in early ACM Digital Library theoretical reviews.
Market Demands and the Real-Time Inference Advantage
The contemporary enterprise software landscape heavily capitalizes on the specific operational advantages of adversarial architectures over modern alternatives. While diffusion models excel at generating hyper-stylized and contextually complex imagery from text prompts, they incur substantial processing penalties due to their multi-step reverse-diffusion mechanics. Conversely, GANs deliver single-step image generation, rendering them ideal for high-throughput enterprise pipelines. This efficiency is a primary reason why software platforms continue to integrate adversarial variants for automated content creation, digital storytelling, and rapid personalization frameworks across the global IT and marketing ecosystems.
A Foundation for Future Generative Innovation
The long-term value of the 2014 breakthrough extends far beyond the standalone usage of vanilla GANs. The core concept of training neural networks through adversarial loss has cross-pollinated other foundational model architectures. Modern hybrid pipelines frequently utilize adversarial discriminators to fine-tune the outputs of diffusion networks or variational autoencoders, ensuring sharper edges and structural fidelity in synthetic image generation. As tech conglomerates and creative agencies scale up their automation efforts to meet regional demands, the principles established by Goodfellow continue to act as a crucial stabilizing and optimizing mechanism for the next frontier of generative artificial intelligence.
What Most Reports Miss: The Architectural Interdependence of Modern Visual AI
The prevailing narrative surrounding generative AI often presents a clean, linear succession where diffusion models entirely replaced the adversarial frameworks of the previous decade. In engineering departments and research laboratories, however, the reality is far more collaborative. The fundamental mechanic pioneered by Ian Goodfellow—pitting neural networks against each other to sharpen outcomes—has not been discarded; it has been internalized. Modern text-to-image generators rely heavily on adversarial loss functions during their final training phases to eliminate the characteristic blurriness of pure diffusion, proving that the competitive dynamic remains essential for achieving true photorealism.
This technical integration highlights a strategic pivot among infrastructure engineers who face a growing crisis of compute costs. While diffusion models excel at understanding complex, semantic text prompts, their iterative nature makes them exceptionally expensive to run at a global scale. By embedding adversarial discriminators into the post-processing layers of these pipelines, developers can drastically truncate the number of denoising steps required to produce a crisp final asset. This hybrid architecture allows enterprise platforms to achieve the conceptual accuracy of modern models alongside the rapid, low-latency rendering speeds traditionally championed by adversarial setups.

From a stakeholder perspective, this technological synthesis has completely reshaped the intellectual property and investment landscape. Early deployment of generative systems faced immense resistance from digital artists and media conglomerates due to the unpredictable, unaligned nature of open-ended generation. The implementation of discriminator-like filtering mechanisms, heavily inspired by Goodfellow's original framework, provided corporate actors with the precise guardrails necessary to commercialize these tools safely. By utilizing secondary networks as automated quality controllers, companies turned a highly volatile research project into predictable B2B software capable of generating brand-compliant assets.
The historical trajectory of this technology also illuminates a profound shift in how artificial intelligence handles human intuition. Prior to 2014, generative models required human engineers to mathematically define what made an image look realistic—an impossible task given the subjective nature of art and perception. Goodfellow’s breakthrough outsourced this definition to the machine itself, allowing the discriminator to build its own internal, evolving rubric of visual authenticity. This philosophical leap from hand-coded rules to learned, adversarial critique is precisely what enabled the tech industry to transition from generating low-resolution faces to synthesizing flawless, high-fidelity digital environments.
Looking forward, the architectural fusion of these competing methodologies points toward a highly optimized future for creative technologies. As localized edge computing becomes the standard for mobile devices and real-time gaming applications, the demand for lightweight, high-performance generative models will continue to escalate. The structural legacy of the adversarial paradigm ensures that as visual AI continues to advance, its progress will remain deeply anchored in the elegant, self-correcting tension of two networks pushing each other toward perfection.
Reading Between the Lines: The Illusion of Linear Progress in Synthetic Media
The tech industry frequently falls prey to the myth of absolute obsolescence, eagerly declaring older architectures dead the moment a more fashionable framework emerges. The prevailing market hype insists that diffusion models and autoregressive transformers have entirely eclipsed the adversarial paradigms of the mid-2010s. Yet, a closer examination of enterprise deployments reveals a stark contradiction: the massive computing demands of pure diffusion are forcing an industry-wide retreat back to the efficiency principles pioneered by early adversarial networks. Companies are discovering that while massive models win headlines for conceptual flexibility, they often fail the strict cost-benefit analyses required for high-volume corporate infrastructure.
This technical friction exposes a major vulnerability in the current venture-capital-driven AI landscape. Investors have poured billions into platforms that require hundreds of computational steps to generate a single second of video or a high-resolution marketing asset. This approach is fundamentally unsustainable for real-time applications like interactive gaming, live broadcast modulation, or on-device mobile synthesis. As a result, engineers are quietly retrofitting modern generative pipelines with adversarial loss functions to bypass these structural bottlenecks. This hybrid reality deflates the popular industry narrative of clean, generational replacement, exposing it instead as a chaotic process of architectural recycling.
Furthermore, the industry's desperate rush toward hyper-realism has introduced an existential paradox regarding data integrity. As adversarial and diffusion models flood the open internet with synthetic imagery, they are inadvertently poisoning the very datasets required to train future iterations of artificial intelligence. This phenomenon, often termed model collapse, reveals a supreme irony: the highly efficient discriminator networks designed to mimic human perception are now being used to filter out the digital garbage generated by their own architectural descendants. The corporate race to automate content creation is systematically destroying the authentic human data footprint that made the initial 2014 breakthrough possible.
Ultimately, projecting the long-term trajectory of visual AI requires a healthy dose of structural skepticism regarding the promises of total automation. The tech sector continues to market these tools as autonomous creative partners, willfully ignoring that they remain entirely dependent on immense human curation and rigid structural constraints to produce coherent outputs. The enduring reliance on adversarial frameworks proves that artificial intelligence cannot yet create in a vacuum; it still requires an internal digital adversary to simulate the critical judgment that machines natively lack. Until architectures can innovate rather than merely optimize, the creative tech industry will remain locked in the same computational loops first formalized over a decade ago.
The true legacy of this generative evolution is not the total displacement of human labor, but the creation of an increasingly complex, self-referential digital ecosystem. As enterprise platforms continue to merge competing methodologies to maximize throughput and minimize overhead, the line between distinct AI epochs will blur entirely. The future of synthetic media belongs not to a single dominant framework, but to a pragmatic, messy synthesis of historical breakthroughs and modern scaling laws, proving that in technology, the past is rarely truly left behind.
"We spent a decade building machines to trick other machines into thinking a digital image was real, only to find ourselves in a multi-billion-dollar industry dedicated to tricking humans into paying for compute cycles they don't actually need."
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments