Why Cathay Financial Is Betting Big on Small Open-Source AI Models

The hype surrounding massive, closed-source artificial intelligence systems is facing a practical reality check in the banking sector. In June 2026, Taiwanese financial giant Cathay Financial Holdings proved that smaller can actually be smarter. By unveiling its latest validation data at the NVIDIA GTC Taipei 2026 conference, the company demonstrated a successful shift toward lightweight, open-source small language models to accurately decode and classify real-time customer intents.
It's a clever play in an industry usually weighed down by immense computational costs and strict regulatory compliance. Operating under its proprietary GAIA generative AI framework, Cathay Financial tested open-source models from major tech players like Meta and NVIDIA alongside localized regional platforms. The results showed that these nimble frameworks can match the accuracy of mainstream proprietary giants while massively reducing system complexity and operational overhead.
Trimming the Fat in Financial AI
Building a customer support system that understands the difference between a routine credit card payment assistance request and an urgent mortgage balance inquiry usually requires a massive digital brain. However, huge models need a lot of expensive hardware and complex engineering to stay accurate. By fine-tuning smaller software packages, the engineering team bypassed complex prompt structures and focused instead on targeted training datasets.
Data privacy is another area where this strategy shines. Rather than risking customer information in public cloud systems, the project utilized a fully synthetic data approach to design local, industry-specific terminology libraries. This lets the algorithms navigate localized language contexts and ambiguous customer queries safely within their own secure ecosystem.

The Real-World Payoff
The practical goal here is to revolutionize the foundation of digital customer engagement. Instead of putting clients through frustrating automated phone trees, these optimized models can act as intelligent routing engines for branch navigation and online services. Cathay Financial is already looking at expanding the technology to handle long-context financial documents and cross-scenario customer service tasks, setting a clear blueprint for cost-effective enterprise AI infrastructure.
The Technical Friction of Going Small
Behind the Scenes: Building a highly specialized financial brain out of open-source components requires more than just downloading a pre-trained model and plugging it into a customer service portal. Financial institutions routinely run into a wall where lightweight models struggle with the dense, highly regulated jargon unique to banking and insurance laws. When Cathay Financial began tuning these smaller architectures, engineers had to bridge the gap between generalized linguistic capabilities and localized financial regulations, a process that usually demands massive, curated training datasets.
To bypass the traditional bottleneck of gathering and cleaning messy, real-world data, the project leaned heavily into generating high-fidelity synthetic data. By using larger foundational models to systematically manufacture realistic customer service interactions, they created a controlled sandbox environment to train the smaller models. This isolated approach not only protected sensitive consumer data from leaking into cloud-based training loops but also allowed developers to intentionally introduce local slang and ambiguous regional phrasing into the training mix.
The operational shift is part of a broader corporate push known as the "GAIA" framework, which acts as a centralized AI playground across Cathay's various financial subsidiaries. Instead of allowing individual branches to spin up separate, fragmented AI projects, this architecture acts as a unified platform. It standardizes how open-source models are evaluated, optimized, and deployed, ensuring that a breakthrough in intent classification for insurance claims can easily be adapted for retail credit card services.
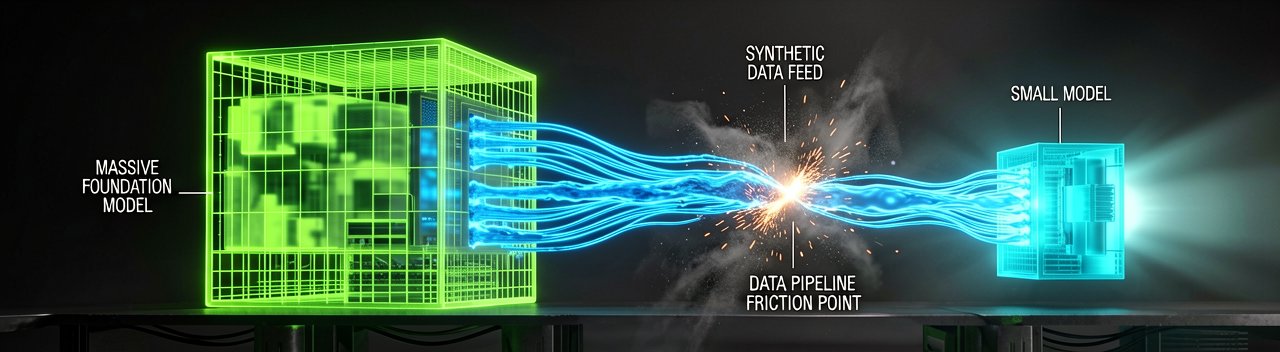
This localized strategy reflects a growing skepticism among corporate Chief Information Officers regarding the long-term pricing stability of proprietary AI vendors. Relying entirely on external application programming interfaces leaves a business vulnerable to sudden API price hikes, service outages, and shifting data privacy policies that can conflict with regional banking rules. Operating fine-tuned open-source models locally gives financial groups full control over their infrastructure costs, security protocols, and hardware lifecycles.
Looking ahead, the enterprise goal is to transition these small language models from passive classification tools into active, multi-step digital assistants. The technical roadmap focuses on expanding their context windows so they can digest complex, multi-page insurance policies or investment portfolios in real time. By keeping the underlying software footprint small, the company aims to embed these intelligent routing systems directly into consumer-facing mobile apps and web platforms without sacrificing system responsiveness or inflating cloud computing bills.
The Hidden Cost of Lightweight Independence
Reading Between the Lines: While the pivot toward open-source small language models is framed as a major victory for corporate frugality, it introduces a subtle paradox in enterprise resource allocation. The marketing narrative promises a massive reduction in operational computing bills by ditching expensive, cloud-hosted proprietary systems. However, this calculation often conveniently leaves out the skyrocketing cost of specialized human talent required to curate synthetic data, maintain local infrastructure, and fine-tune these delicate open-source architectures over time.
There is also a glaring contradiction in relying on massive, commercial foundation models to generate the very synthetic datasets used to train their smaller, open-source replacements. Essentially, financial institutions are still deeply tethered to the tech giants they claim to be breaking away from during the development phase. If a proprietary model introduces hidden biases or factual hallucinations into the synthetic training mix, those flaws become permanently baked into the smaller model's logic, making troubleshooting a nightmare.
Furthermore, deploying lightweight models into the unpredictable wild of real-time customer service exposes the strict limits of their linguistic reasoning. A model optimized for a narrow set of banking intents can easily be thrown off by a customer using unconventional metaphors or venting complicated, multi-layered grievances. When an algorithmic shortcut fails, the system must gracefully hand the conversation over to a human operator, meaning the old, expensive human safety nets cannot be dismantled anytime soon.
The long-term risk for the financial sector is a quiet fragmentation of technology standards under the guise of data sovereignty. As every major institution builds its own siloed variation of open-source software, the industry moves further away from a unified framework for AI safety and compliance. For now, small models are an excellent band-aid for reducing API dependency, but they remain a stepping stone rather than a permanent cure for the complex headache of enterprise artificial intelligence.
"In the corporate rush to replace expensive, multi-billion-parameter cloud models with nimble, homegrown alternatives, banks may soon realize they have simply traded a hefty monthly subscription fee for a permanent, full-time staff of AI babysitters."
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments