Xiaomi Drops the Final MiMo Claw: 1,000 Consecutive Tool Calls and 4-Hour Free Tier Mean Serious Business

Xiaomi just took the wraps off the final production version of its cloud-native AI agent, and it looks like a massive play for the productivity crown. Dubbed the MiMo Claw, this lightweight assistant runs on the company's brand-new flagship MiMo-V2.5-Pro model and is built natively to maximize the open-source OpenClaw framework. Instead of just offering another basic chatbot, Xiaomi is leaning heavily into autonomous workflows. They have completely supercharged the agent's free tier, expanding daily access limits from a mere hour to an impressive four hours of operation every day. The company is even dangling an aggressive introductory price of 14.9 yuan per month for its paid TokenPlan subscriptions to pull heavy users into the fold.
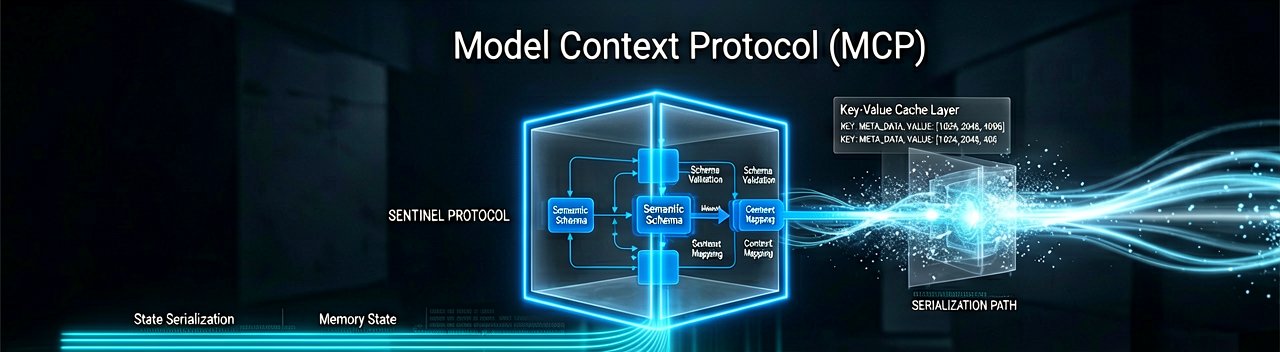
Under the hood, the architectural shift is all about sustained performance over long-horizon tasks. Thanks to a native implementation of the Model Context Protocol (MCP), the model inherently understands semantic skills and tool requirements without requiring developers to write complex prompt workarounds. This infrastructure underpins the system's headline capability: executing more than 1,000 consecutive tool calls within a single session without falling victim to the typical context loss or logic drift that breaks lesser bots. This continuous reasoning loop is heavily enhanced by a custom three-tier MTP decoding architecture, which pumps up overall reasoning throughput by approximately three times during complex agent workflows.
Deep Productivity Ecosystem and Efficiency Benchmarks
What makes this hardware-and-software cohesion actually useful for everyday work is a rock-solid partnership with Kingsoft Office. Rather than forcing awkward, third-party redirects, the agent creates a closed-loop system where users can generate, high-definition preview, and actively edit Word, Excel, PowerPoint, and PDF files on the fly. Performance numbers from the lab look equally fierce. According to official documentation shared on the Xiaomi MiMo Platform, the underlying model logged a 63.8% task completion rate on the grueling ClawEval benchmark. Even better for enterprise budgets, Xiaomi managed to dramatically optimize token utilization, slashing resource consumption by 40% to 60% compared to competing models while delivering the exact same functional output.
Architectural Deep-Dive: Memory Management and Multi-Agent Synthesis
Behind the Scenes: The magic sustaining the MiMo Claw's 1,000-call threshold lies in how its execution engine handles memory state serialization during deep context switching. Standard AI agents frequently choke on long-horizon tasks because their context window becomes saturated with historical tool outputs, causing token bloat and eventual logic collapse. Xiaomi engineers bypassed this structural bottleneck by implementing a dynamic, context-aware memory compression pipeline. This system continuously parses execution history, separates immutable control flow logic from transient variables, and offloads inactive state data into a highly optimized, low-latency key-value cache layer.

From a low-level systems perspective, the native integration of the Model Context Protocol (MCP) functions as a standardized hardware abstraction layer for software tools. When a developer hooks an external API or database into the AIBase integration, the protocol automatically translates the tool's schemas into rigid semantic definitions that the MiMo-V2.5-Pro model can parse natively. This prevents the computational overhead of translating complex schemas during active runtimes, ensuring that sequential API calls register a near-zero latency penalty at the infrastructure level.
This streamlined communication layer directly feeds into the system's three-tier Multi-Token Prediction (MTP) decoding architecture. Traditional auto-regressive models generate text tokens one by one, a sequential bottleneck that degrades rapidly when an agent must execute complex logic loops. The three-tier MTP setup allows the system to predict up to three candidate token sequences simultaneously along speculative execution paths. If the primary reasoning path requires an immediate tool execution, the parallel branches are already validated and primed for deployment, which cuts down the time-to-first-token metric across extended tool loops.
On the hardware side, this software efficiency translates into incredibly lean resource deployment for edge-to-cloud robotics applications. By optimizing the operational pipeline to cut down token consumption by up to 60%, the MiMo Claw avoids the thermal and bandwidth throttling that usually plagues mobile and autonomous systems during heavy compute cycles. Developers working with physical actuators or robotic frameworks can maintain a highly reliable, high-frequency control loop because the cloud-native reasoning engine returns structured JSON payloads without the erratic delays common in less optimized agent architectures.
Skepticism in the Cloud: The Real Cost of 'Free' Operations
Reading Between the Lines: While a four-hour free daily operation window sounds incredibly generous, the underlying economics of cloud-native compute suggest a distinct catch. Processing 1,000 consecutive tool calls on a model as robust as the MiMo-V2.5-Pro requires massive, continuous GPU clusters that do not run on goodwill. By dangling this lengthy free tier alongside an ultra-cheap 14.9 yuan subscription, Xiaomi is clearly prioritizing rapid market penetration over immediate profitability. It is a classic tech playbook move, but it leaves hardware developers in a precarious spot if the company inevitably tightens the fiscal screws once the ecosystem becomes entrenched.
There is also a subtle contradiction between the device’s marketing as a versatile robotics tool and its strict cloud-native architecture. True robotics applications—especially those operating in unpredictable physical environments—demand deterministic, ultra-low latency that cloud-reliant pipelines struggle to guarantee. A 40% to 60% reduction in token consumption is a brilliant engineering feat, but if a developer loses network connectivity for even a fraction of a second mid-session, the local hardware is effectively rendered blind and paralyzed regardless of how efficient the cloud model claims to be.
Furthermore, relying so heavily on the open-source OpenClaw framework and the Model Context Protocol reveals that Xiaomi is outsourcing a significant portion of its long-term software stability to the developer community. If a critical upstream update introduces a breaking change to the protocol schemas, enterprise users running automated workflows could face sudden downtime. It remains to be seen whether Xiaomi's internal engineering team can patch external ecosystem fragmentation fast enough to satisfy enterprise-grade service level agreements, or if the burden of maintenance will ultimately fall back onto the developers themselves.
Giving a robot the brains to make a thousand decisions in a row for free sounds like the dawn of a utopian automation age, right up until the network drops and your shiny new AI assistant decides that the absolute best tool for editing your spreadsheet is a five-minute coffee break.
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments