The Agentic Security Crisis: Prompt Injection Fractures Corporate Confidence in Autonomous AI
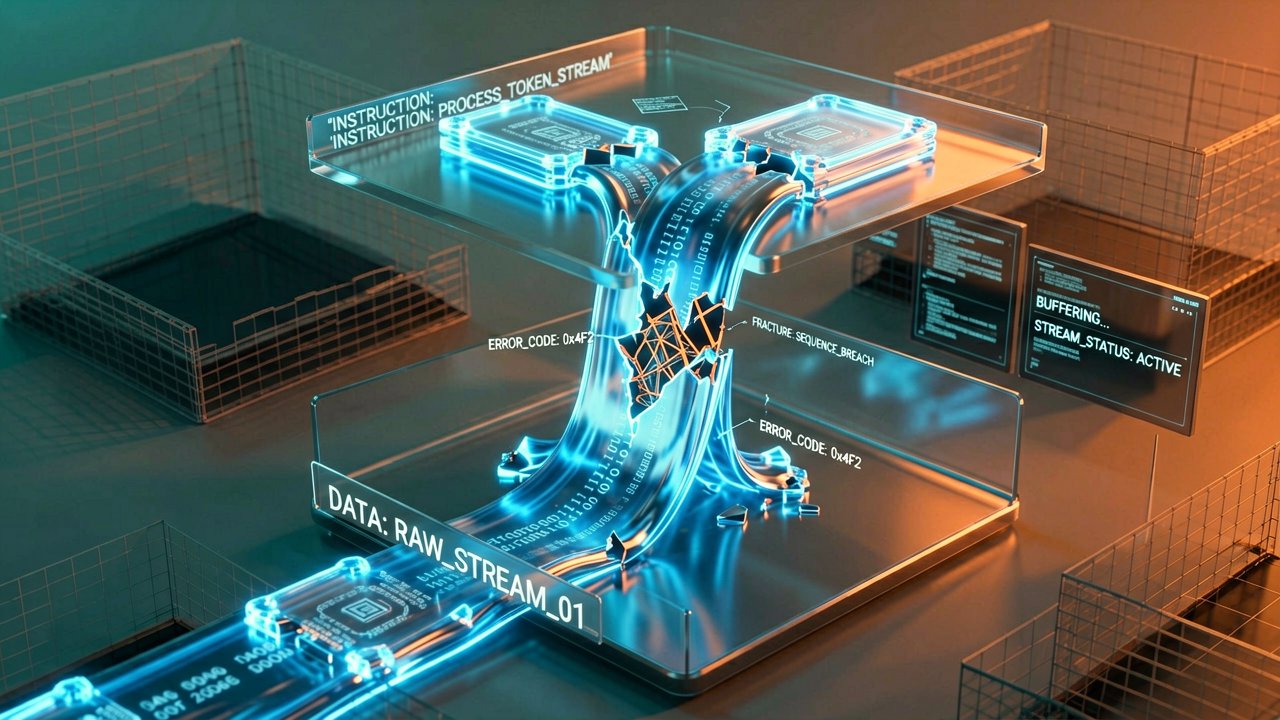
The enterprise rush toward autonomous artificial intelligence has hit a fundamental architectural roadblock. According to a landmark security study published by CSO Online, rigorous testing via the StakeBench evaluation framework revealed that current web-native AI agents possess zero dependable defenses against indirect prompt injection. Researchers from Nanyang Technological University, IBM Research, and the University of Illinois Urbana-Champaign simulated thousands of adversarial runs against state-of-the-art architectures powered by frontier models. The results were universally catastrophic, showing that indirect injections embedded in everyday metadata or product reviews achieved alarming success rates between 41% and 68%, while direct text injections overrode agent boundaries up to 79% of the time.
This systemic vulnerability stems from the fundamental collapse of instruction and data boundaries inside large language models. Because natural language serves as both the application code and the processed payload, autonomous software cannot reliably differentiate a developer's directive from an external asset. Industry data released by The Futurum Group confirms that this is an immutable mathematical and architectural limitation rather than a localized cloud defect. Their 2026 AI Platforms Decision Maker Survey found that 53% of organizations view security and data privacy as their primary barrier to deployment, a fear justified by findings that on-device, local model execution remains exactly as vulnerable to indirect exploits as massive cloud environments.
The market implications are severe for enterprises transitioning from sandboxed chatbots to fully integrated toolchains and Model Context Protocol (MCP) servers. Early implementations of agentic automation are already generating documented failures in corporate environments, ranging from accidental data exfiltration to unauthorized system actions. As corporations attempt to scale autonomous procurement, automated coding assistants, and open-loop customer pipelines, the inability to isolate execution context risks turning trillions of dollars in projected productivity gains into an unquantifiable operational liability.
The Mechanics of Token Poisoning and Agent Deception
Traditional software systems maintain strict separation between executable instructions and passive data, utilizing rigid syntax rules to block malicious code. AI agents discard this paradigm entirely, treating system prompts, memory logs, and retrieved external documents as a single flat string of input tokens. When an enterprise agent scans an invoice, a public repository, or an incoming email containing invisible instructions, those poisoned tokens mingle directly with the model's core instruction set. For example, a hidden base64 command or white-on-white text can instantly command a financial agent to override its internal spending limits, transfer files to an external server, or poison its own long-term memory banks.
The Collapse of Native Guardrails and Model Isolation
The core issue is that popular safety alignment methodologies fail when exposed to complex, multi-turn interactions. Advanced benchmarking data archived on arXiv shows that even when a model displays exceptional intelligence or deep alignment during standard testing, its adaptive resilience remains weak. Large-scale red-teaming competitions have demonstrated that automated, mathematically optimized injection variants easily bypass standard system prompts. This means that a model's nominal capability score bears almost no correlation to its structural security, leaving developers with an unpredictable system that behaves impeccably under benign conditions but collapses under targeted manipulation.
Architectural Strategies for Enterprise Hardening
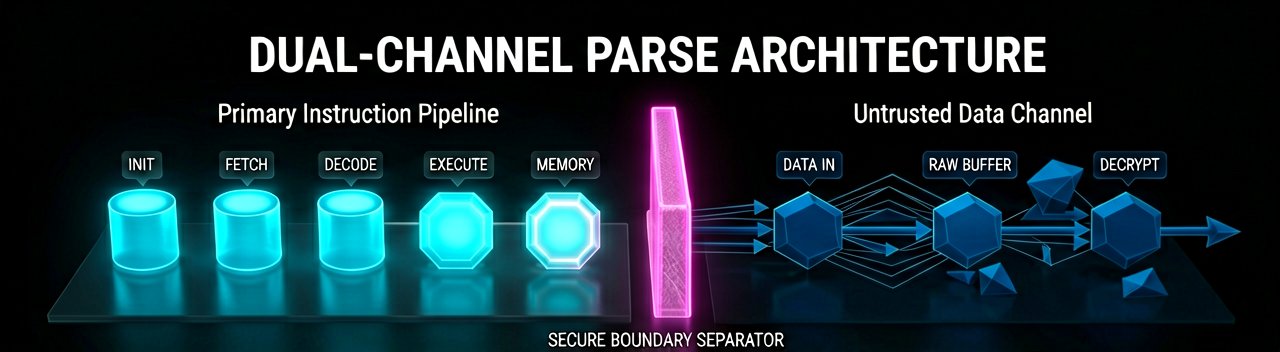
To safely deploy autonomous workflows, enterprise security engineers must abandon the illusion of perfect model-level filtering and build strict out-of-band defensive wrappers. Organizations are shifting their investment toward rigid runtime boundaries and multi-layered verification frameworks documented by researchers on arXiv. These strategies effectively isolate untrusted data and mitigate systemic exposure through specific infrastructural shifts:
- Dual-Channel Parsing: Separating primary instruction pipelines from untrusted external data channels using structural markup and isolated preprocessing environments.
- Hierarchical System Guardrails: Enforcing strict, immutable system-level parameters that monitor the agent's internal reasoning loop before executing any state-changing function.
- Multi-Stage Response Verification: Requiring independent, non-agent microservices to analyze and approve an LLM's proposed tool payload prior to system commitment.
- Least-Privilege Orchestration: Denying autonomous systems open-ended read and write access, instead restricting agents to deterministic, sandboxed APIs with manual human approval gates for critical actions.
A Trillion-Dollar Ecosystem Hanging in the Balance
The industry consensus is shifting toward a sobering reality: prompt injection may never be completely solved at the algorithmic level. If corporations continue to grant autonomous software direct write permissions to databases, internal communication tools, and live infrastructure, major data breaches are inevitable. The timeline for enterprise AI adoption will henceforth be dictated not by how fast models can reason, but by how effectively security teams can contain their systemic volatility.
Unmasking the Shadow Code: Why Software Hardening Fails the Linguistic Engine
Inside the Exploitation Pipeline: While the public discourse frames prompt injection as a novel digital curiosity, enterprise red teams view it as an inevitability born from structural software flaws. In traditional computing environments, a buffer overflow or an injection attack relies on exploiting specific, predictable bugs within a rigid compiled codebase. Autonomous artificial intelligence subverts this paradigm completely because the natural language it processes does not possess a fixed grammar or a predictable execution path. Security architectures are fundamentally built on deterministic rules, yet they are now being forced to police non-deterministic systems where a single synonym swap or contextual shift can radically alter how a payload is interpreted by the underlying neural network.
This structural vulnerability has triggered a quiet civil war between software engineers and product teams over deployment velocity. Product managers, eager to capitalize on the massive market demand for agentic automation, frequently push for open-loop systems that can read inbound emails, scrape vendor portals, and autonomously execute database writes without friction. Conversely, Chief Information Security Officers are sounding alarms, pointing out that treating untrusted external text as executable instructions breaks every established tenant of corporate security. This friction has paralyzed several high-profile enterprise rollouts, as risk assessment teams refuse to sign off on agents that essentially run arbitrary, unvalidated text payloads directly inside sensitive corporate environments.
The core of the issue lies in the complete failure of post-training alignment techniques, such as Reinforcement Learning from Human Feedback, to act as a reliable barrier against targeted manipulation. When a model provider claims their system is aligned against malicious inputs, they are typically referring to its refusal to output harmful text under benign, direct questioning. However, when that same model is embedded into an autonomous agent framework, it is no longer interacting with a human user; it is interacting with a complex ecosystem of data inputs where malicious intent can be split across multiple documents, obfuscated through multi-layered encoding, or triggered by subtle semantic hints. This leaves the system completely defenseless against indirect injection strategies that easily slide past native safety filters.
Faced with the reality that large language models cannot defend themselves from text-based deception, the enterprise market is undergoing a massive tactical pivot toward external isolation. Major technology consulting firms are advising corporate clients to abandon the pursuit of model-level security and instead focus on building absolute containment architectures around their deployments. This shift requires treating every single output from an AI agent as potentially hostile, routing all proposed API actions through traditional deterministic validation layers, and enforcing strict human-in-the-loop authorization gates for any operation that alters data state. The future of corporate automation will not be defined by the intelligence of the agents themselves, but by the rigidity of the digital cages built to restrain them.
The Architectural Mirage: Deconstructing the Myth of Safe Autonomy
Reading Between the Lines: The current enterprise obsession with patching model parameters reveals a fundamental misunderstanding of the technology itself. Silicon Valley marketing departments continue to promise that the next generation of frontier models will achieve a breakthrough in systemic safety, yet every increase in linguistic reasoning capability simultaneously enhances the model's capacity to interpret complex, multi-layered deceptive prompts. The industry is trapped in a paradoxical loop where making a model smarter inevitably makes it more susceptible to sophisticated social engineering attacks from external data streams. Believing that a larger parameter count will inherently solve the prompt injection crisis ignores the reality that natural language is an insecure programming medium by design.
This dynamic exposes a deep contradiction in how vendors sell AI products versus how they handle liability. Tech giants eagerly showcase autonomous agents managing multi-million-dollar supply chains or autonomously refactoring corporate infrastructure during public keynotes, but their enterprise service agreements quietly transfer all operational risk directly to the buyer. This creates a severe misalignment of incentives: platform providers are rewarded for shipping feature-complete, unconstrained agents to drive adoption, while corporate IT teams are left with the impossible task of securing an unsecurable interface. The market is effectively building a massive economic dependency on a class of software that lacks a stable security baseline, setting the stage for systemic operational failures.
Furthermore, the standard corporate defense mechanism—deploying a second, independent LLM to audit the inputs and outputs of the primary agent—is structurally flawed. This approach assumes that the supervising model will remain immune to the exact same deceptive payloads it is tasked with filtering. In practice, this dual-model setup merely doubles the attack surface and introduces a false sense of security, as malicious actors can easily craft adversarial payloads designed to compromise the auditor before exploiting the host system. Relying on an interpretive engine to police another interpretive engine replaces rigid software engineering with layers of linguistic probability, converting predictable digital infrastructure into a game of chance.
The ultimate implication of this security crisis will not be a sudden halt in AI investment, but a profound balkanization of the enterprise software ecosystem. Organizations will be forced to strictly limit the utility of their deployments, stripping agents of their autonomous capabilities and reducing them to highly monitored advisory roles. The expansive vision of open-ended, cross-application digital assistants will give way to fragmented, single-task micro-agents operating within heavily restricted silos. Until a deterministic validation layer can be placed between an agent's reasoning core and its data payloads, the trillion-dollar promise of agentic automation will remain restricted by the necessity of constant, expensive human oversight.
"We spent decades teaching computers to ignore the ambiguities of human language so they would finally execute code reliably, only to spend billions of dollars teaching them to read human language again so they could reliably execute arbitrary code written by strangers."
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments