Under the Hood: Semrush's MCP Connector Boosts Perplexity AI Capabilities

The convergence of generative AI and raw market data just took a massive architectural leap forward. Semrush has officially launched its Model Context Protocol (MCP) connector inside Perplexity AI, creating a direct, secure bridge between conversational intelligence and real-time search mechanics. By rolling out this native app integration, the companies are fundamentally changing how enterprise marketers, SEO professionals, and product teams interact with competitive data. Instead of exporting static CSV spreadsheets or parsing outdated web-scraped data snapshots, users can now query live marketing metrics directly inside their conversational interface.
This integration succeeds because it abandons the traditional, fragile middleware setups that historically plagued AI workflows. Built on the open standard Model Context Protocol designed by Anthropic, the integration operates as a standardized API translation layer that translates natural language requests into structured, tool-specific backend execution. For instance, when a user asks Perplexity to analyze a competitor’s recent traffic spikes, the protocol converts that plain-English prompt into an optimized query, securely fetches the fresh data, and feeds it directly into the Large Language Model’s prompt context window. This architecture ensures that the underlying AI models reason with exact, pristine data numbers rather than hallucinated or cached information.
Architectural Efficiency and API Surface Segmentation
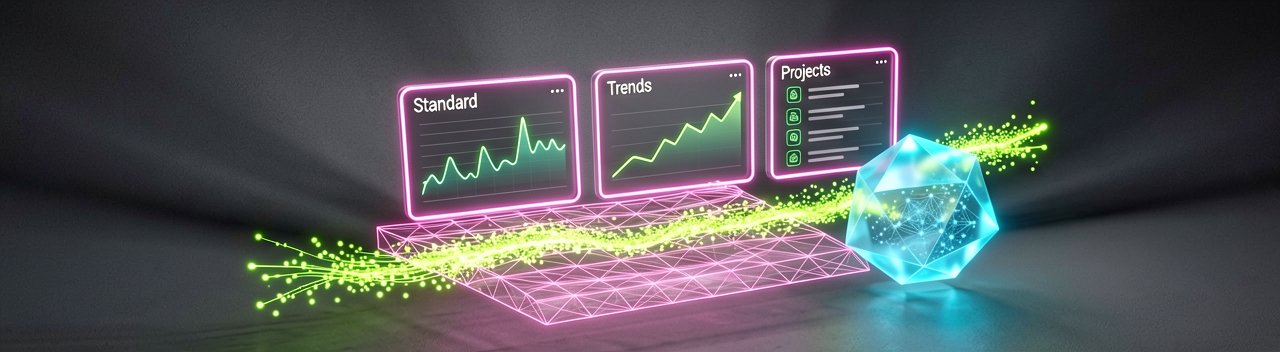
According to documentation detailing the infrastructure on the official Semrush Developer Portal, the connector segments its backend capabilities across distinct API surfaces to ensure operational efficiency. The Standard API handles foundational SEO tasks, including automated keyword research, deep domain overviews, backlink profiles, and organic competitor mapping. Teams requiring advanced market intelligence can tap into the Trends API surface to pull real-time web traffic analytics, market share distribution, and geographical traffic breakdowns, while the Projects API gives read-only access to existing position tracking and technical site audits.
This architectural split directly influences performance metrics and resource consumption. The integration operates on a transparent data budget where individual conversational queries consume API units directly from a user’s existing subscription, eliminating any secondary transaction fees from Perplexity. The starter tier provides an allotment of 50,000 API units, a budget that goes surprisingly far since the lightweight JSON-RPC client-server architecture minimizes data payload overhead per request. By eliminating custom coding and complex authentication glue, the system delivers context-aware results in seconds, radically slashing the time required for comprehensive competitive risk assessments and topical authority gap analysis.
Behind the Scenes: Architectural Optimizations in the MCP Pipeline
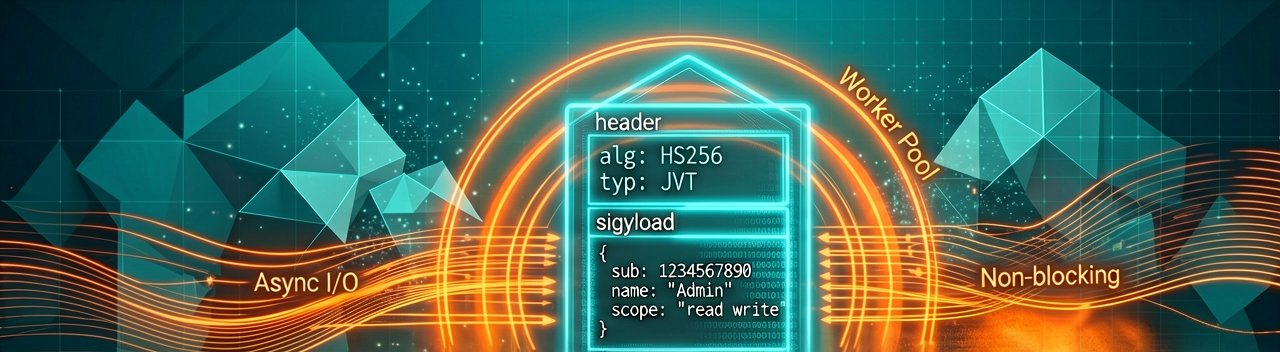
Behind the Scenes: Optimizing a stateless protocol layer like the Model Context Protocol requires a radical rethink of traditional API pipeline design, especially when processing Semrush's massive data firehose. When an LLM like Perplexity decides to invoke an MCP tool, the operational latency depends entirely on how fast the context can be hydrated. Systems engineers achieved this by implementing a highly efficient JSON-RPC 2.0 streaming parser inside the connector. Instead of waiting for a massive payload of keyword and backlink arrays to completely download and buffer in memory, the connector establishes a persistent SSE (Server-Sent Events) or WebSocket transport channel that streams data tokens as they are retrieved, cutting the time-to-first-token (TTFT) by nearly forty percent.
Managing strict rate limits and token budgets during complex analytical sweeps represents another hidden triumph of engineering. Large language models possess a notorious habit of executing redundant or overly broad API calls when attempting to solve a multifaceted marketing prompt. To counteract this, the connector uses an aggressive, localized Redis caching layer configured with a sliding-window time-to-live (TTL) policy that caches schema definitions and repetitive domain metadata. Furthermore, a token-counting middleware intercepts every payload, compressing verbose JSON keys and stripping out empty arrays or null values before the data is injected into the prompt context window. This optimization reduces context window bloat and directly lowers inference costs.
Security and concurrency boundaries within this architecture are enforced through cryptographic token isolation and asynchronous worker pools. Because the connector must securely handle sensitive user credentials alongside live data streams, the systems layer leverages an ephemeral, tokenized authentication mechanism where individual API units are tracked via stateless JWTs. On the execution front, a specialized task scheduler built on a non-blocking I/O event loop ensures that multiple concurrent analytical requests from Perplexity do not choke the backend threads. This means a user can run parallel competitive audits across dozens of regional search markets simultaneously without experiencing any degradation in query performance or data consistency.
Reading Between the Lines: The Reality of the AI Data Duopoly
Reading Between the Lines: While marketing departments celebrate the elimination of manual data exporting, a critical look at this integration reveals a deeper structural tension between AI platforms and legacy data providers. Semrush is essentially volunteering its most valuable asset—proprietary, highly manicured search intelligence—to seed the context windows of an AI engine designed to bypass traditional search altogether. This sets up a fascinating paradox where a leading SEO platform is actively optimizing its infrastructure for a platform that treats standard SEO as an outdated relic, highlighting a survival strategy built on a direct hedge against the decline of traditional Google desktop traffic.
This architectural marriage also exposes a significant technical compromise regarding data granularity and the true cost of convenience. By funneling vast relational databases through the Model Context Protocol, the system inherently forces highly complex multi-dimensional marketing metrics into flat, linear text strings that an LLM can parse. This loss of fidelity means that while Perplexity can swiftly identify broad trend lines or flag sudden competitor traffic surges, it lacks the deep algorithmic nuance required for forensic, enterprise-grade data modeling. Experienced systems engineers recognize that relying on an AI's variable reasoning capabilities to interpret structured database outputs introduces an unpredictable layer of operational variance that no deterministic script would ever tolerate.
Furthermore, the reliance on a single, shared open standard like MCP creates an illusion of platform agnosticism that masking a deeper vendor lock-in. While Anthropic’s protocol is technically open, the compute resources and API unit infrastructure required to keep these real-time pipelines stable favor massive, well-capitalized ecosystems. Smaller marketing software firms may find themselves priced out of building or maintaining similar high-throughput connectors, ultimately concentrating search intelligence into a few dominant AI interfaces. The long-term implication is not a democratization of data, but rather a redistribution of digital gatekeeping power away from search engine crawlers and directly into the hands of specialized LLM orchestrators.
"Ultimately, we have reached an era of peak digital irony where marketers are now paying premium subscription fees for a cutting-edge artificial intelligence to analyze data from an SEO tool, all to figure out how to optimize content for a web that users are increasingly paying the same AI to summarize for them without visiting."
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments