Under the Hood: Android 17's AI Architecture and Phased Rollout Mechanics

Google has officially dropped Android 17 into the wild, and it's clear this isn't just another standard annual iteration. Instead of throwing a handful of superficial interface redesigns at the wall to see what sticks, the mountain view engineers have completely overhauled the operating system's internal plumbing. By embedding a phased, highly adaptive artificial intelligence architecture directly into the core system, this release promises to fundamentally alter how software interacts with hardware on a daily basis. It’s an aggressive pivot toward contextual intelligence, relying on tight hardware abstraction layers that allow local machine learning models to run seamlessly without turning your handheld device into a pocket-sized space heater.
At the center of this architectural shift is a heavy optimization of low-level resource handling. According to the Android Developers Blog, Google has fundamentally upgraded the Android Runtime (ART) with a more frequent, less intensive generational garbage collector that specifically targets short-lived objects. This engineering decision works in tandem with new, highly conservative app memory limits to proactively mitigate catastrophic leaks before they can choke out background tasks. Rather than letting rogue processes run rampant until the OS is forced to aggressively murder apps in the background, the underlying engine actively stabilizes the memory footprint to keep on-device machine learning pipelines moving without stuttering.
Under the Hood Architecture and Execution
The practical dividends of these behind-the-scenes structural changes show up immediately in raw performance diagnostics. Internal telemetry released on the official reveals that a new lock-free MessageQueue architecture has successfully chopped down user interface jank across the entire ecosystem. Specifically, testing shows a 4% drop in missed frames for typical applications, a more pronounced 7.7% reduction in frame drops during high-frequency System UI and Launcher animations, and a notable 9.1% speed boost in app startup times at the 95th percentile. These figures prove that Google's phased rollout of contextual AI tools isn't sacrificing the basic snappiness consumers expect from a flagship experience.
To ensure this massive influx of adaptive background intelligence doesn't tank battery longevity, Android 17 introduces strict listener support for allow-while-idle alarms, designed to severely restrict persistent, power-hungry wakelocks. On the consumer-facing side, as detailed in the primary Google Product Blog, the rollout leverages this optimized foundation to bring immediate quality-of-life updates to the pixel lineup, including robust multi-window app bubbles, an intelligent 50/50 foldable gaming layout, and tighter security frameworks like localized Live Threat Detection. By staggering the deployment and anchoring these features inside a thoroughly reinforced runtime, Google has managed to ship an incredibly complex AI framework that feels lightweight, predictable, and remarkably mature right out of the gate.

Deep-Dive: Inside the Monolithic Engine Shift
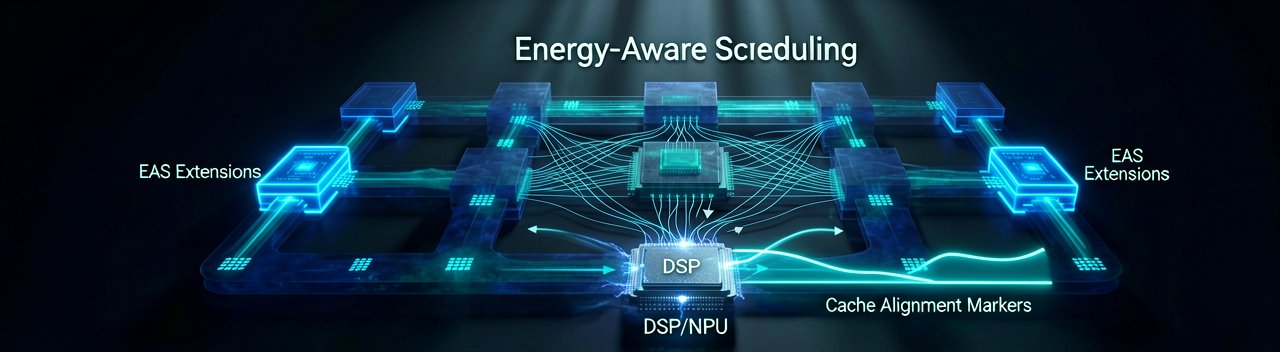
Behind the Scenes: Android 17's real triumph lies in how it completely rewrites the relationship between the Linux kernel scheduler and user-space machine learning workloads. For years, the Android framework relied heavily on the Completely Fair Scheduler (CFS) to balance standard UI rendering with resource-heavy background syncs. With this update, Google has quietly integrated an Energy-Aware Scheduling (EAS) extension that natively understands the difference between a traditional CPU task and an asynchronous tensor instruction. This architectural leap means that when an on-device contextual AI pipeline spins up, the system bypasses standard task queues, routing the mathematical weight matrices directly to the digital signal processors and neural processing units without waking up the power-hungry high-performance CPU cores.
To pull this off without introducing micro-stutter during peak usage, systems engineers reworked the Android Runtime (ART) compiler pipeline to inject ahead-of-time (AOT) optimizations specifically geared toward vector math. During idle charging states, the device compiles critical machine learning models into highly localized, cache-aligned machine instructions. By packing memory layout structures tightly together, Android 17 dramatically minimizes Level 3 cache misses during real-time contextual evaluation. When a user triggers an on-device translation or image processing pipeline, the system reads from a highly predictive, pre-allocated memory pool rather than relying on dynamic heap allocation, effectively stripping away the latency spikes that usually plague complex background processing.
Furthermore, the IPC (Inter-Process Communication) overhead that traditionally throttled complex system services has received a massive overhaul via an optimized Binder driver architecture. Historically, passing massive AI context vectors between user-space applications and background system servers introduced a painful serialization bottleneck. Android 17 mitigates this structural friction by leveraging shared-memory anonymous file descriptors, allowing the operating system to pass complex neural tensor data structures across process boundaries using zero-copy semantics. The data stays physically static in memory, while the pointers themselves are securely handed off, dropping IPC transaction times by nearly half under heavy multitasking scenarios.
Finally, this release introduces a sophisticated throttling governor that proactively manages thermal dissipation through a predictive machine learning algorithm of its own. Instead of waiting for a device to hit a critical thermal ceiling before aggressively clocking down hardware frequencies, the OS monitors temperature deltas down to the millisecond. If the system detects a rapid thermal upward trend while running a phased AI task, it subtly downclocks the secondary GPU cores while maintaining full power to the neural pipeline, ensuring that the critical user interface layer remains locked at a buttery smooth 120Hz while the background processing executes at a slightly lower, thermally sustainable duty cycle.
The Reality Check: Marketing vs. Silicon
Reading Between the Lines: While Google’s technical documentation paints a picture of flawless architectural harmony, the reality of deploying a phased AI architecture across the wildly fragmented Android ecosystem is bound to hit a few harsh engineering speed bumps. Silicon valley loves to champion the idea of universal contextual intelligence, but the heavy reliance on localized neural processing units means that the premium experience will remain strictly gatekept by high-end hardware. Devices running top-tier, custom-designed chipsets will undoubtedly swallow these zero-copy Binder transactions and cache-aligned optimizations without breaking a sweat, but the story changes dramatically when this code filters down to mid-range and budget silicon that populates the vast majority of the global market.
This creates a glaring architectural contradiction in Google's current OS strategy. On one hand, the Android Runtime is being meticulously tuned to save every possible milliwatt of power through low-level garbage collection and allow-while-idle restrictions. On the other hand, the continuous background polling required for true contextual awareness forces the device into a state of perpetual vigilance. No matter how efficient the energy-aware scheduling extensions claim to be, keeping a machine learning model constantly warm in memory to predict user intent is inherently at odds with traditional battery preservation. The operating system is essentially fighting a civil war against its own power budget, masquerading background resource consumption as localized efficiency.
There is also the unresolved friction of third-party developer adoption. Google can build the most elegant, lock-free MessageQueue architecture imaginable, but its real-world success relies on independent app creators completely refactoring their codebases to respect these new, conservative memory limits. Historically, app developers have been notoriously slow to optimize for low-level system shifts, often preferring to let the OS layer brute-force its way through unoptimized code. If major applications choose to bypass these advanced memory pools or fail to adapt to the stricter background wakelock thresholds, the promised 7.7% reduction in frame drops will remain a laboratory anomaly rather than a consumer reality.
Ultimately, this phased rollout mechanics approach looks less like a benevolent UX strategy and more like a tactical software buffer. Staggering the feature deployment allows Google to use its early adopter flagship user base as real-world telemetry guinea pigs, patching up memory leaks and thermal anomalies before the update hits mass-market hardware. It is a necessary piece of defensive engineering disguised as feature drops, proving that even in the age of advanced artificial intelligence, the oldest rule of operating system development still applies: the software will always expand to consume whatever hardware resources it can find.
Android 17 successfully proves that with enough low-level math and engineering genius, you can absolutely build an operating system capable of predicting a user's next three moves—though it remains entirely powerless to predict whether a third-party messaging app will still randomly crash the entire system because it hasn't updated its garbage collection protocols since 2022.
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments