The End of the Chat Freeze: Hermes Agent Taps Asynchronous Subagents for Fluid Multitasking

Anyone who has spent serious time wrangling autonomous AI agents knows the inevitable, teeth-grinding frustration of the interface freeze. You delegate a complex task, and suddenly your main chat window transforms into a digital brick, completely unresponsive until the subagent finishes churning through its code. It is an engineering bottleneck that has broken the illusion of seamless human-AI collaboration for years. However, the team at Nous Research is actively shattering that roadblock. The latest development commit for their open-source framework introduces an asynchronous subagent architecture, a design shift that effectively cuts the cord between active user interaction and background task delegation.
Instead of locking the terminal or messaging UI while a delegated process executes, the updated Hermes Agent handles multi-step pipelines via an asynchronous fire-and-forget execution strategy. When a user requests a heavy background task—like generating a series of platform-specific marketing assets or diagnosing continuous integration failures—the primary agent instantly spins up an isolated subagent within its environment registry. Because these subagents operate independently in background containers, users can comfortably continue chatting, tweaking configurations, or managing entirely separate workstreams without waiting for a spinning loading wheel to resolve. It changes the operational dynamic from a rigid, sequential back-and-forth into something resembling a fluid, multi-threaded operating system.
From Background Churn to Blazing Metrics
This structural evolution does more than just fix an annoying user interface quirk; it radically alters the agent's performance profile. Early benchmarks highlighted by tech observers on platforms like MarkTechPost point to a dramatic reduction in idle workflow latency, effectively maximizing token processing throughput across concurrent tasks. By moving away from sequential blockades, the architecture enables the agent to continuously ingest new user context while concurrently leveraging its persistent memory layers and local SQLite search engines. For developers deploying the framework on minimal virtual private servers or serverless infrastructure, this non-blocking approach ensures that compute cycles are spent processing parallel pipelines rather than stalling out on a frozen gateway loop.
Behind the Scenes: The Micro-Architectural Blueprint
Behind the Scenes: Achieving true non-blocking execution inside an LLM orchestration layer requires a structural departure from traditional, stateful loops. Systems engineers building on the framework immediately notice how the engine decouples state management from the active runtime execution environment. Instead of keeping a monolithic process open while waiting for external API calls or deep search loops to complete, the architecture delegates tasks to dedicated agent runtimes operating inside isolated background containers. These containers communicate with the primary interface via a lightweight, non-blocking asynchronous event loop, ensuring that the main execution thread never blocks on I/O operations.
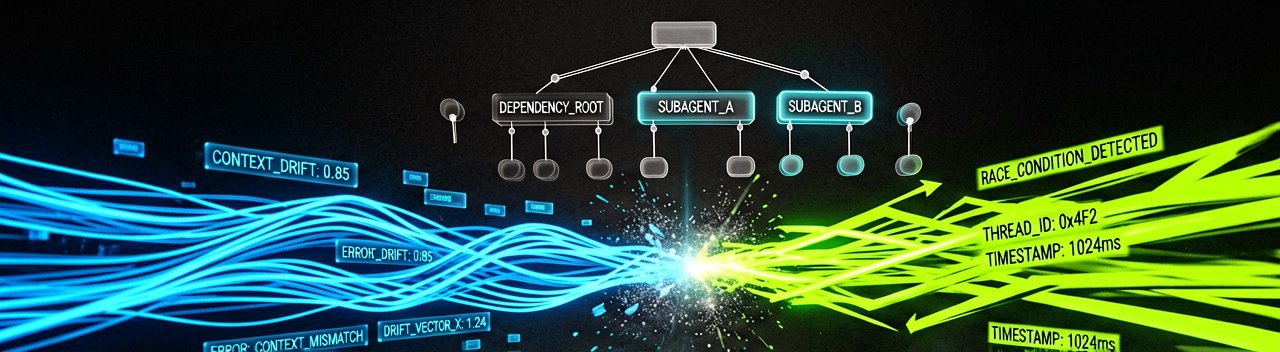
To prevent concurrent subagents from stepping on each other's toes or causing race conditions during file system updates, the engine implements a persistent SQLite-backed storage layer that operates on strict isolation principles. When an independent worker is instantiated, it receives a read-only snapshot of the current conversational state and active environment context. Any workspace mutations or newly discovered data structures are written back to individual, localized delta tables. The core agent then merges these deltas back into the main pipeline using structured conflict-resolution rules only when the subagent signals a clean execution exit code.
This design drastically reduces compute overhead during parallel pipelines by relying on an intelligent fire-and-forget task delegation pattern. Rather than polling an active subagent for updates—which introduces unnecessary network chatter and wastes token processing budget—the primary orchestration hub uses async event listeners. A subagent registers its task within the internal registry, spins up its execution thread, and works silently in the background. The primary system can immediately accept new input vectors from the user or initiate unrelated tool calls while the background worker processes its payload asynchronously.
Memory optimization represents another critical engineering victory within this updated pipeline. Instead of passing massive context windows back and forth through expensive network requests, subagents leverage cross-process shared references to specific local search engines and memory indices. By indexing local files and token hierarchies on the fly, the worker nodes avoid redundant data processing cycles. This ensures that even when multiple specialized workers are hunting for anomalies across system logs or compiling long-form code snippets, the host machine maintains a highly stable memory footprint.
The ultimate byproduct of this isolated, containerized design is a dramatic surge in total execution throughput. By breaking out of the sequential execution trap, the framework transitions from a simple, conversational utility into a resilient, multi-threaded operating environment. Complex multi-step automation scripts that used to time out or freeze user-facing operations now execute smoothly behind the curtain, letting users manage active workflows while their digital assistants handle the heavy computational heavy lifting in parallel.

Reading Between the Lines: The Reality of Asynchronous Autonomy
Reading Between the Lines: While the promise of an unblockable chat interface sounds like a localized triumph for user experience, it introduces a labyrinth of hidden architectural costs that the tech industry is notoriously eager to gloss over. The immediate assumption is that multi-threading an AI agent yields linear productivity gains. In reality, shifting from synchronous loops to an asynchronous fire-and-forget framework merely trades a user-interface bottleneck for a complex orchestration nightmare. When you give independent subagents the freedom to roam in the background, you are no longer just managing an AI model; you are managing a distributed system prone to state drift and race conditions.
The core contradiction lies in the intersection of asynchronous execution and deterministic logic. Traditional software architectures rely on strict, predictable states to ensure background workers do not corrupt data or overwrite active variables. Large language models, by their very nature, are probabilistic engines that excel at hallucinating subtle deviations when re-prompted. Throwing multiple autonomous workers into a shared environment means your primary agent is left to reconcile conflicting, non-deterministic outputs from subagents that finished their tasks out of order. It creates a scenario where the UI remains beautifully responsive, yet the underlying workspace risks devolving into a digital house of mirrors.
Furthermore, the claim of optimized compute efficiency warrants a healthy dose of skepticism from systems architects. While local SQLite delta tables and container isolation protect the immediate memory footprint of the host machine, they do nothing to curb the exponential API token drain. A non-blocking UI naturally encourages users to queue up multiple heavy background pipelines simultaneously. Each independent container spin-up requires its own context injection, context window management, and iterative validation loops. Far from saving resources, this architecture is a massive accelerator for operational costs, quietly burning through token budgets behind a sleek, un-frozen chat screen.
Projecting this trend forward suggests that the real challenge of future AI development is shifting away from prompt engineering and moving entirely toward advanced conflict resolution. If frameworks like Hermes continue to decouple user interaction from subagent execution, developers will need to spend less time worrying about model alignment and significantly more time building complex state-reconciliation algorithms. Without these defensive guardrails, the long-term viability of asynchronous delegation will collapse under the weight of its own uncoordinated autonomy, transforming helpful assistants into unpredictable background wildcards.
Giving an AI agent the ability to spin up un-blocking background workers is a brilliant engineering feat right up until you realize you have effectively handed a credit card and a set of car keys to three invisible toddlers who are all trying to remodel your kitchen at the same time.
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments