Mastering Layout-Aware Parsing: A Technical Breakdown of Docling Parse's Pipeline Architecture
For years, enterprise document processing has been haunted by the "word salad" problem. Standard text extraction tools routinely strip away formatting, leaving multi-column financial statements or multi-page medical records jumbled into an illegible mess. It is an industry-wide headache that makes downstream Retrieval-Augmented Generation (RAG) and generative AI applications stumble over basic layout structures. Enter Docling Project, an open-source toolkit engineered to treat documents not just as strings of text, but as visually structured data environments.
At the absolute core of this ecosystem is its specialized backend engine, which handles the messy reality of unstructured data with a sophisticated, multi-stage processing pipeline. Rather than guessing where text belongs, the architecture starts with a dedicated format-specific backend. For PDFs, the system deploys a specialized engine to retrieve programmatic text tokens alongside their exact geometric coordinates, while simultaneously rendering a bitmap image of each page. This hybrid approach ensures that downstream AI models have access to both raw text metadata and high-fidelity visual representations, establishing a rich foundation for layout-aware intelligence.
The Local AI Pipeline and Table Management
Once the initial text and image primitives are extracted, the system routes the data through a sequential model pipeline that runs entirely on local hardware. The layout analysis stage relies on advanced object detectors, such as the Heron layout model based on the RT-DETRv2 and DFINE architectures, which isolate structural elements like headings, paragraphs, and figures. When a table structure is identified, its specific image crop and text cells are passed directly to TableFormer. This cell-level table extraction engine predicts structural hierarchies and matches cells back to the original PDF coordinates, skipping the computationally expensive step of re-transcribing text from scratch. Finally, an aggregation stage determines the natural reading order, infers the document's language, and builds a unified object that developers can cleanly serialize into Markdown or JSON.
Throughput Realities and Performance Metrics
Understanding how this architecture behaves under enterprise workloads requires looking at real-world computational trade-offs. According to detailed pipeline evaluations published in the Docling Technical Report, processing complex tables on standard CPUs typically takes between 2 and 6 seconds per table, scaling linearly with the density of the included cells. It is a highly predictable operational profile, though the performance dynamics change significantly when pushing the system through hardware accelerators.

When operations move to a GPU, the resource breakdown highlights where the processing bottlenecks actually live. Benchmark data shared within the developer community on GitHub shows that the pipeline hits its maximum throughput of roughly 3.3 pages per second when both OCR and Vision-Language Model (VLM) extensions are turned off. Activating the VLM drops throughput to about 0.83 pages per second, while enabling both OCR and VLM components throttles processing speed down to 0.64 pages per second. Profiling metrics reveal that the VLM swallows up roughly 58% of the pipeline execution time, with OCR accounting for another 38%. Interestingly, increasing the batch size from 4 to 256 offers zero throughput improvement—it merely inflates VRAM usage without a speed payoff—making concurrency management the true key to scaling this architecture efficiently.
Behind the Scenes: Memory Architecture and VRAM Saturation
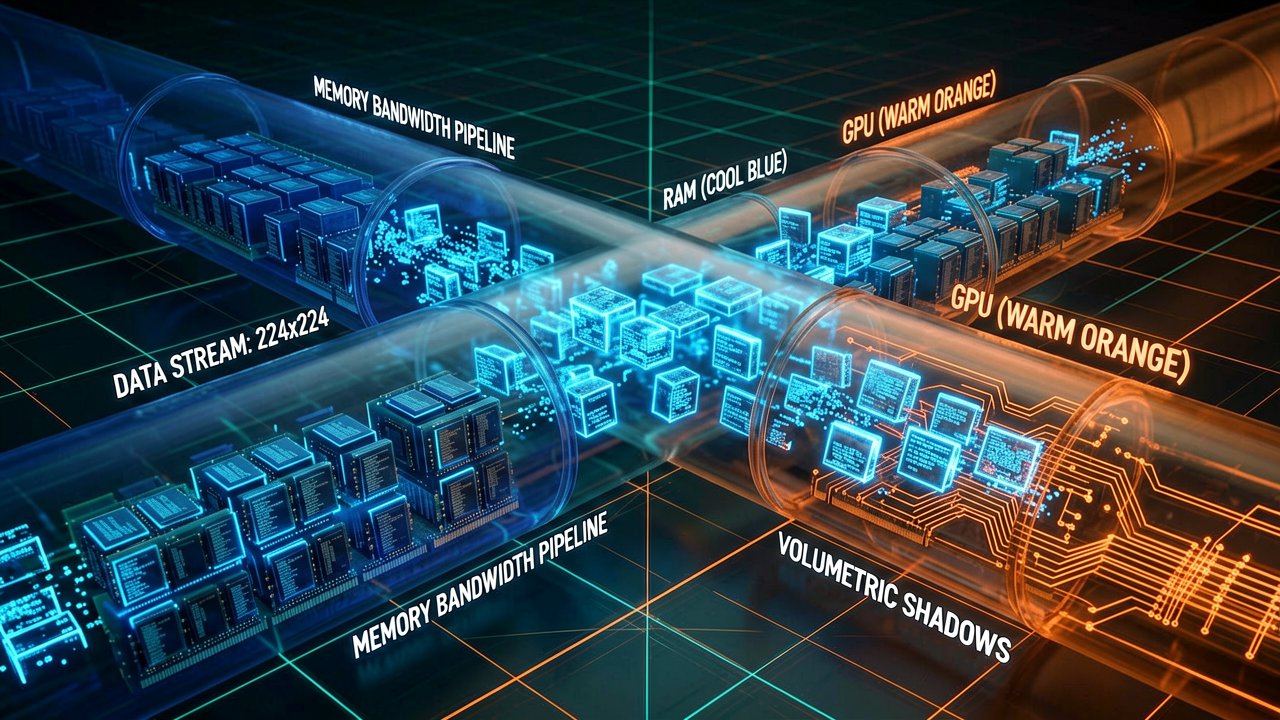
Optimizing this layout pipeline for enterprise throughput shifts the engineering challenge from pure machine learning to meticulous system-level resource allocation. At the hardware layer, the local AI pipeline behaves strictly as a memory-bandwidth-bound application, meaning that raw compute cycles on a modern GPU are rarely the primary bottleneck. Instead, performance hinges on the constant shuttling of heavy vision primitives—specifically the 224x224 or 384x384 image patches extracted during layout analysis—between host system RAM and the high-bandwidth memory (HBM) of the accelerator card. Systems engineers must tightly manage this serialization boundary to prevent PCIe bus saturation from stalling the execution pipeline.
Because increasing the batch size beyond a critical threshold yields diminishing returns, standard parallelization techniques like native PyTorch data-parallel wrappers fail to optimize this specific workload. A massive batch size like 256 fails to boost throughput because the pipeline relies on a cascading series of heterogeneous models, where the output of the layout detector dynamically dictates the input dimensions for the TableFormer and OCR modules. This unpredictability fragments memory, causing the GPU's memory manager to constantly allocate and deallocate VRAM segments. To maintain the maximum baseline throughput of 3.3 pages per second, architectures require an asynchronous queue system that isolates each model stage into its own worker process, maintaining dedicated, pre-allocated VRAM pools that completely bypass runtime garbage collection delays.
On the text processing front, the backend relies on structural coordinate matching rather than standard visual OCR, saving massive amounts of compute. By directly querying the programmatic PDF text stream for character bounding boxes, the engine eliminates the need to run heavy convolutional or transformer-based text recognizers over the entire page layout. The visual OCR engine is kept dormant, spinning up only when the system encounters a page area that lacks digital font metadata, such as a scanned chart or an embedded JPEG image. This selective execution strategy keeps the average processing time per page consistently lean, preventing the 38% computational tax of full OCR from triggering across standard digital documents.

When the vision-language model extensions are enabled, the structural processing paradigm shifts dramatically toward deep tensor parallelism. The VLM component introduces massive multi-head attention layers that demand up to 58% of the total pipeline execution budget, making it the most expensive bottleneck in the system. To prevent this stage from starving the upstream text extraction and layout detection processes, engineers implement a double-buffering architecture. While the GPU executes the forward pass of the VLM on a processed chunk of pages, the CPU concurrently handles the geometric token extraction and image rendering for the next block of documents, establishing a fluid assembly line that keeps hardware utilization balanced across both processors.
Reading Between the Lines: The Reality of Layout Autonomy
The enterprise rush to adopt layout-aware parsing is built on a seductive premise: that open-source AI can seamlessly translate any legacy corporate document into structured digital gold. Yet, examining the operational trade-offs reveals a glaring disconnect between marketing promises and actual pipeline behavior. While achieving a baseline throughput of 3.3 pages per second sounds impressive for a local setup, that metric only holds true when the engine is running in what is essentially a lobotomized state—completely stripped of OCR and vision-language extensions. The moment a business confronts real-world data, such as a skewed scan or a highly stylized PDF report, the throughput drops by over 80 percent, exposing the fragile economic reality of hosting these processing pipelines at scale.
This massive performance drop forces infrastructure engineers into a difficult architectural compromise. If you optimize purely for speed by turning off the vision-language extensions, your RAG applications become vulnerable to hallucinations caused by misaligned reading orders in complex multi-column layouts. Conversely, if you prioritize parsing accuracy by enabling the full VLM stack, your computational costs skyrocket while processing speeds collapse to less than a single page per second. This reality directly contradicts the widespread industry assumption that local AI parsing pipelines are a cheap, drop-in replacement for proprietary cloud APIs. When memory fragmentation and VRAM saturation demand dedicated, high-end GPU hardware just to process document queues at a reasonable clip, the total cost of ownership shifts dramatically.
Furthermore, the reliance on structural coordinate matching from the underlying PDF text stream introduces its own set of hidden vulnerabilities. The pipeline assumes that the programmatic text tokens inside a digital PDF are inherently accurate and well-ordered. In practice, corporate documents are frequently generated by flawed automated systems that embed scrambled font mappings or invisible, chaotic text layers beneath the visual interface. When the parser encounters these digital anomalies, its coordinate matching mechanism faithfully extracts garbage data, leaving the system completely blind to the error unless the computationally punishing OCR engine is explicitly forced to re-verify the entire page layout. It is a structural catch-22: trusting the digital stream introduces silent data corruption, while distrusting it destroys processing throughput.
Projecting this landscape forward suggests that the ultimate bottleneck in enterprise automation is no longer the intelligence of the parsing models, but the chaotic nature of human document design itself. Organizations will eventually have to accept that throwing heavier local models at arbitrary, poorly formatted layouts yields diminishing returns. True scalability will not come from inventing more complex table-matching architectures or buying larger VRAM pools to host demanding VLMs. Instead, it will require a pragmatic shift toward rigid Document-as-Code standards at the source, forcing a structural compromise between the humans who generate reports and the layout-aware systems tasked with reading them.
"We have spent billions of dollars building incredibly sophisticated neural networks capable of deciphering complex multi-column tables, all to solve a structural crisis that could have been prevented entirely if someone had just banned the use of the spacebar for text alignment thirty years ago."
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments