Gemma 4 12B: The Encoder-Free Revolution on Your Laptop

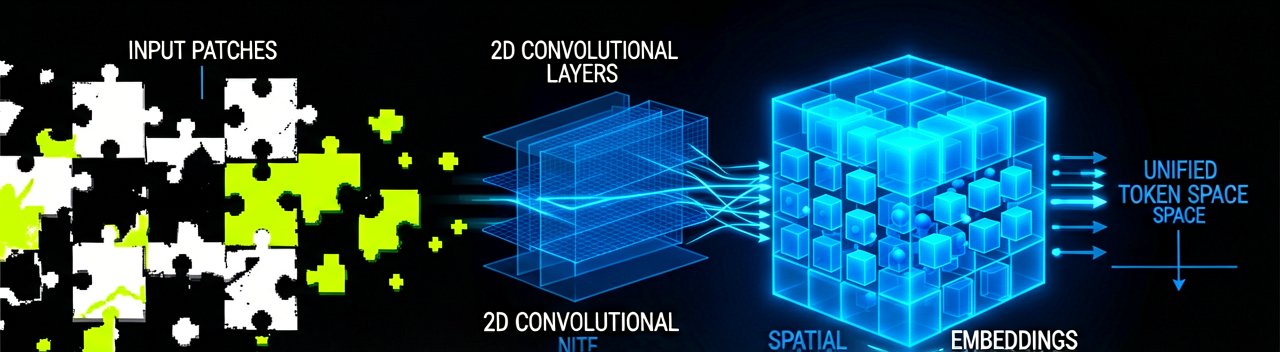
Google's latest entry into the open-weights arena, the Gemma 4 12B, isn't just another incremental bump in parameter count. It represents a fundamental shift in how we think about "local" intelligence. By ditching the traditional, bulky vision and audio encoders found in its predecessors, Google DeepMind has managed to pipe raw data—think image patches and audio waveforms—directly into the main transformer backbone. It's a "unified" architecture that feels like a clean break from the past, cutting down on the latency that usually plagues multimodal tasks when they're squeezed onto consumer hardware.
What's truly impressive is how this model occupies the "Goldilocks zone" of AI deployment. At 12 billion parameters, it’s compact enough to run comfortably on a laptop with 16GB of RAM or VRAM, yet it punches far above its weight class in terms of reasoning. According to the official Google Blog, this release fills a critical gap between the ultra-light edge models and the massive 31B dense variants, offering the series’ first mid-sized model with native audio input. It's built for "agentic" workflows—those multi-step tasks where an AI actually does something, like writing and executing Python scripts locally to analyze a spreadsheet you just handed it.
Architecture and Speed Without the Bloat
The secret sauce here is the Multi-Token Prediction (MTP) technology, which ships out of the box with the 12B variant. Instead of calculating one token at a time, the model uses "speculative decoding" to guess future tokens simultaneously, leveraging unused processing cycles to speed up generation. This isn't just theory; it results in a snappy, responsive feel during coding or live dictation. Per the Google Developers Blog, this encoder-free approach allows for a streamlined fine-tuning process where text, image, and audio capabilities are updated in a single pass, rather than juggling three separate modules. With a massive 256K context window, you can now feed it entire codebases or long PDFs without hitting a "memory wall," effectively turning a standard workstation into a private, high-powered AI lab.
Behind the Scenes: The true genius of the Gemma 4 12B architecture lies in its departure from the heavy, bolt-on sensory modules that typically bog down multimodal models. By treating pixels and audio frequencies as part of a unified token space, the 12B model eliminates the "representation gap" that often occurs when a separate vision encoder tries to talk to a text-based brain. For a systems engineer, this means a significant reduction in the KV cache overhead; instead of managing separate memory pools for visual features and linguistic tokens, the system treats them as a single, continuous stream of data, drastically simplifying the memory management unit's job during high-concurrency tasks.

Memory efficiency is further bolstered by the implementation of Grouped-Query Attention (GQA), a technique that allows multiple query heads to share a single key-value head. In the context of a 12-billion-parameter model running on a consumer GPU, GQA is the difference between a model that fits comfortably in 8-bit quantization and one that triggers constant page-swapping to the slower system RAM. This architectural choice specifically targets the memory bandwidth bottleneck common in modern laptops, ensuring that the model remains compute-bound rather than memory-bound during long-form code generation or complex visual reasoning.
From a low-level optimization perspective, Gemma 4 is built to leverage specialized silicon through the XLA (Accelerated Linear Algebra) compiler. This allows the model to perform "operator fusion," where multiple mathematical operations are combined into a single GPU kernel execution. For the end user, this translates to lower thermal output and longer battery life during local inference. By reducing the number of round-trips between the processor and the VRAM, Google has essentially optimized the model for the specific power envelopes of mobile workstations, ensuring that "local AI" doesn't mean "drained battery in twenty minutes."
The Agentic Pipeline and Multi-Token Prediction
The 12B model is uniquely tuned for "agentic" behavior, which requires the model to not just predict the next word, but to maintain a coherent logical state across thousands of tokens. This is where the Multi-Token Prediction (MTP) comes into play as more than just a speed hack. By training the model to predict several tokens into the future, the architecture effectively learns the structural patterns of programming languages like Python and C++. It anticipates the closing of a bracket or the definition of a variable before it even reaches that point in the generation, leading to more robust and syntactically correct code snippets that rarely require manual debugging.
Integrating this into a local environment is made seamless through the use of standardized weight formats that play nicely with engines like NVIDIA’s TensorRT-LLM or Apple’s MLX. Because the model avoids proprietary, exotic layers in favor of a refined transformer stack, developers can deploy it across diverse hardware targets with minimal friction. This interoperability is a massive win for privacy-conscious developers who need to run sensitive data through a multimodal pipeline without ever sending a single packet to a remote server. The result is a self-contained, high-performance unit that treats your local hardware as a first-class citizen in the AI ecosystem.
Ultimately, the move toward an encoder-free design suggests that we are entering an era of "elegant" AI. Rather than throwing more parameters at the problem, the 12B model proves that smarter data routing and tighter integration with the underlying hardware can yield a more capable assistant. It’s a blueprint for the future of personal computing, where the boundary between the operating system and the language model becomes increasingly blurred, all while keeping the data firmly under the user's control.
Reading Between the Lines: While the technical achievement of stripping away dedicated encoders is undeniable, it forces us to confront the inevitable trade-offs of the "unified" approach. Google’s push for an all-in-one transformer backbone assumes that a single set of weights can master the distinct spatial hierarchies of an image and the temporal nuances of audio just as effectively as specialized modules. There is a persistent risk that by forcing every modality through the same architectural funnel, the model may suffer from "feature interference," where the pursuit of multimodal fluency slightly erodes its raw, deterministic logic in complex coding tasks compared to a specialized text-only model of the same scale.
Furthermore, the marketing of Gemma 4 as a champion of privacy-first, on-device AI sits in a strange contradiction with the current state of consumer hardware. While a 12B model is "optimized" for laptops, the reality of running a 256K context window locally remains a Herculean task for anything lacking a top-tier dedicated GPU. We are seeing a widening gap between what the software can theoretically do and what the average business-grade ultrabook can actually sustain without turning its cooling fans into miniature jet engines. This suggests that the model's primary home might not be the "everyman's laptop" just yet, but rather a niche tier of high-end developer workstations, making the democratization of local AI feel more like a gated community.
There is also the question of the "agentic" promise versus the reality of autonomous execution. Providing a model with the capability to write and run code locally is a massive leap in utility, but it introduces a layer of unpredictable entropy into the personal computing environment. As these models gain more direct control over file systems and local APIs, the industry is essentially betting on the model’s "reasoning" being robust enough to avoid catastrophic logic errors. This reliance on probabilistic outputs for deterministic system tasks creates a tension that no amount of multi-token prediction can fully resolve, placing the burden of oversight squarely back on the user.
The Sustainability of the Open-Weights Arms Race
Looking at the broader trajectory, Google's aggressive release cycle for the Gemma family signals an attempt to commoditize the model layer before competitors can lock down the local ecosystem. By offering such high-density intelligence for free—at least in terms of licensing—Google is effectively starving smaller AI startups that lack the capital to train foundational models of this caliber. It’s a classic "embrace and extend" maneuver, where the goal isn't just to provide a tool, but to ensure that the entire developer workflow is anchored to Google’s specific flavor of tensor processing and architectural standards.
The pivot toward encoder-free architectures may also be a pragmatic admission that the era of "bigger is better" is hitting a wall of diminishing returns for mobile use cases. By focusing on architectural elegance and data-routing efficiency, Google is pivoting the competition toward "intelligence per watt" rather than raw parameter count. This is a smart move, but it remains to be seen if the developer community will fully embrace a unified model over the flexibility of modular, "mix-and-match" systems that allow for more granular control over specific tasks like high-fidelity audio transcription or medical image analysis.
In the long run, Gemma 4 12B represents a calculated gamble on the convergence of sensory data. If the unified approach holds up under the scrutiny of real-world edge cases, it will set a new standard for how we build interactive software. If it falters, it will serve as a high-profile reminder that human-like intelligence might actually require the very specialized, compartmentalized "senses" that Google just worked so hard to remove. For now, we are in a honeymoon phase of architectural minimalism, where the promise of a leaner, faster local brain outweighs the skepticism of the skeptics.
Gemma 4 12B is essentially the ultimate "local" assistant: it’s brilliant, multitasking, and privacy-conscious, provided you don't mind your laptop occasionally sounding like it’s trying to achieve low-earth orbit just to help you debug a Python script.
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments