Beyond the Digital Alchemist: Teaching AI the Real Laws of Chemistry
For decades, the marriage of computing and chemistry felt more like a long-distance relationship than a true partnership. We’ve had powerful simulations, sure, but most traditional models were essentially fancy calculators that didn't "understand" why a molecule behaved a certain way—they just crunched the numbers we gave them. Now, the tide is turning. A new breed of AI isn't just memorizing chemical structures; it’s being built to respect the fundamental physics that govern our universe. We’re moving away from "black box" models that guess and toward systems that inherently grasp concepts like valence, electronegativity, and spatial geometry.
The real breakthrough lies in Graph Neural Networks (GNNs) and geometric deep learning. By treating atoms as nodes and bonds as edges, researchers are training models to predict molecular properties with startling accuracy. But it’s not just about raw speed. The goal is to solve the "generalization" problem—the tendency for AI to fall apart when it encounters a molecule unlike anything in its training set. By embedding physical constraints directly into the architecture, scientists ensure the AI doesn't propose "hallucinated" molecules that would be impossible to synthesize in a real lab. It’s the difference between a parrot mimicking speech and a chemist who understands the periodic table.
The Physics-Informed Revolution
What makes this shift so compelling is the move toward "physics-informed" neural networks. Instead of treating chemistry as a pattern-recognition task—much like how ChatGPT treats language—these models use loss functions that penalize violations of physical laws. If a model suggests a carbon atom with five bonds, the system knows it’s wrong before it even finishes the calculation. This grounded approach is proving vital for drug discovery and materials science, where the cost of a "wrong" prediction isn't just a typo, but millions of dollars in wasted laboratory resources. As noted by experts at Nature Reviews Chemistry, the integration of these fundamental principles is what will finally allow AI to navigate the vast, unexplored map of chemical space with true reliability.
We are also seeing a massive push in "active learning" loops. In this setup, the AI identifies which experiments it’s most uncertain about, prompts a robotic lab to run those specific tests, and then feeds the results back into its own training set. This creates a self-correcting cycle that shrinks the time required to develop new catalysts or battery electrolytes from decades to months. It isn't just automation; it’s an evolution of the scientific method itself, where the silicon and the test tube are finally speaking the same language.
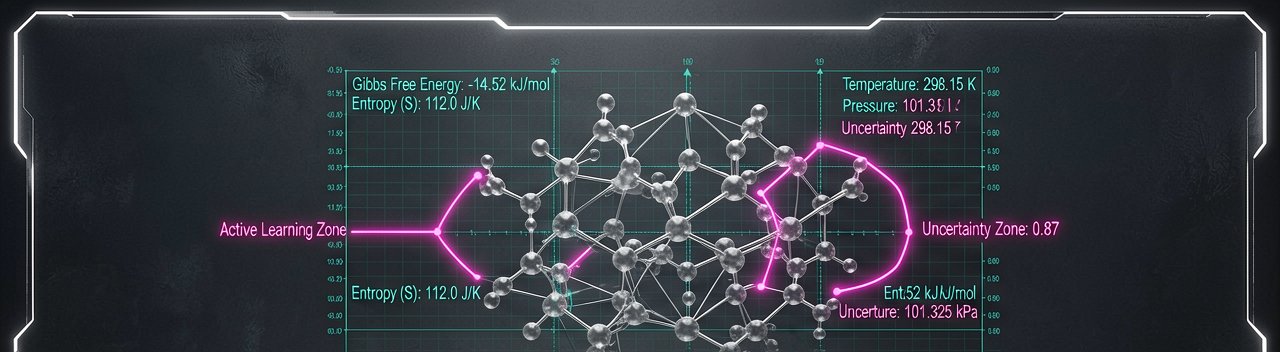
Bridging the Gap Between Code and Carbon
The High-Stakes Reality Check: While the promise of AI-driven chemistry often sounds like science fiction, the industry is currently grappling with a sobering "reality gap." For years, pharmaceutical giants and materials scientists relied on Quantitative Structure–Activity Relationship (QSAR) models—the equivalent of using a map with half the roads missing. These traditional tools were excellent at spotting patterns in known data but notoriously failed when asked to innovate. Today’s shift toward physics-informed neural networks is an attempt to give the AI a "compass" of physical laws, ensuring it doesn't just chase statistical ghosts but actually navigates the constraints of the real world.
The technical hurdle that most reports gloss over is the "small data" problem. Unlike Large Language Models (LLMs) that feast on the entire internet, high-quality chemical data is sparse, expensive, and often locked behind corporate silos. A single experimental data point for a complex reaction can cost thousands of dollars to produce. Consequently, the industry is pivoting toward hybrid models that use what we do know—the laws of thermodynamics and quantum mechanics—to supplement what the data doesn't show. This "theory-trained" approach allows models to generalize from a few hundred examples rather than millions, a necessity for developing niche materials or tackling rare diseases.
From the perspective of a seasoned medicinal chemist, the skepticism isn't about the AI's speed, but its "manufacturability." It’s easy for a generative model to dream up a "miracle" molecule that perfectly fits a protein pocket, but it’s quite another to actually build it. If the suggested synthesis requires conditions that are too dangerous—like highly exothermic reactions that risk a lab explosion—the AI's "brilliance" becomes a liability. Leading researchers, as highlighted by LinkedIn Science Insights, are now prioritizing models that incorporate safety and cost-of-goods metrics directly into the design phase.
Historically, the field has moved from simple regression in the 1960s to the current era of Graph Transformers, but the human element remains the final arbiter. Stakeholders are increasingly advocating for "Intelligence Augmentation" (IA) rather than pure AI. In this paradigm, the algorithm acts as a high-powered digital assistant that whispers possibilities, but the human chemist makes the final call on whether a reaction is worth the risk. This collaborative loop is already paying off, with some robotic platforms performing 1,000 experiments in just 10 days—a pace that would have taken a human researcher a career to complete only a decade ago.
The Friction Between Silicon and Solder
Reading Between the Lines: The industry’s current infatuation with "autonomous labs" often ignores the messy, entropic reality of physical chemistry. There is a persistent assumption that if we simply feed enough quantum mechanical descriptors into a transformer architecture, the "black box" will eventually output a universal theory of everything. However, this overlooks the fact that chemical data is notoriously "noisy." A reaction that works in a climate-controlled lab in Basel might fail in a humid facility in Mumbai because of trace impurities or subtle pressure variances that current AI models simply aren't programmed to care about. We are building Ferraris of computation to drive on dirt roads of experimental inconsistency.
There is also a growing contradiction in how we value "AI-discovered" breakthroughs. While venture capitalists herald the speed of these models, the regulatory landscape remains stuck in a pre-digital era. A model might identify a novel drug candidate in weeks, but the clinical trial process—the grueling human gauntlet of safety and efficacy—remains a decade-long endeavor. Speeding up the "discovery" phase without addressing the "validation" bottleneck is like installing a jet engine on a bicycle; you reach the brick wall much faster, but you’re still hitting a wall. The bottleneck has shifted from ideation to the physical reality of biology, which does not care about Moore’s Law.
Furthermore, the push for "interpretable" AI in chemistry often hits a philosophical snag. We want models to tell us why a catalyst works, yet the very power of deep learning lies in its ability to navigate high-dimensional spaces that the human brain cannot visualize. If we force these models to stick strictly to human-understandable "chemical intuition," we might be inadvertently clipping their wings. We are essentially asking a supercomputer to explain the secrets of the universe using only the vocabulary of a 19th-century textbook. The real tension lies in deciding whether we want an AI that thinks like a chemist, or one that thinks like the universe itself.
Ultimately, the long-term implication isn't the replacement of the scientist, but the commoditization of insight. As these tools become ubiquitous, the competitive advantage shifts from who has the best algorithm to who has the most reliable hardware and the cleanest proprietary data. The prestige of the "brilliant chemist" is being traded for the efficiency of the "brilliant system integrator." It’s a shift from the romantic era of the lone inventor to the industrial era of the high-throughput pipeline, where the most valuable skill isn't knowing the answer, but knowing how to ask a question that the machine can actually solve.
Teaching a computer the laws of thermodynamics is a noble pursuit, but until an AI can figure out how to clean a sticky round-bottom flask without breaking it, the humans are probably safe for another decade or two.
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments