AWS AgentCore Optimization Enters Preview with Automated Agent Tuning
Amazon Web Services has officially announced AgentCore Optimization in public preview, a new capability designed to close the gap between AI agent evaluation and actual performance improvement. The feature completes what AWS describes as an "observe, evaluate, improve loop" for production agents running on Amazon Bedrock.
AI agents that perform well at launch don't stay that way. As models evolve, user behavior shifts, and prompts get reused in contexts they were never designed for, agent quality quietly degrades. In most teams, the improvement process still looks the same: without automatic feedback loops, when a user complains, a developer reads through traces, forms a hypothesis, rewrites the prompt, tests a handful of cases, and ships the fix. Then the cycle repeats, often introducing a new issue for a different user. Up until today, Amazon Bedrock AgentCore provided the pieces for you to debug it manually or build custom implementations.
The developer becomes the performance engine relying on intuition rather than on systematic data-backed evidence. Dedicated science teams and large centralized benchmarks help, but they are neither a practical nor timely solution for most product teams. Even when you have that machinery, it tends to move on weekly or monthly cycles, while agents drift in production every day (a problem that has plagued users for years, frankly).
Today we are announcing new capabilities in AgentCore that complete the observe, evaluate, improve loop for agent performance and quality: recommendations and two ways to validate them. According to the official announcement from AWS Machine Learning Blog, the system now generates recommendations from production traces, validates them with batch evaluation and A/B testing, and ships with confidence.
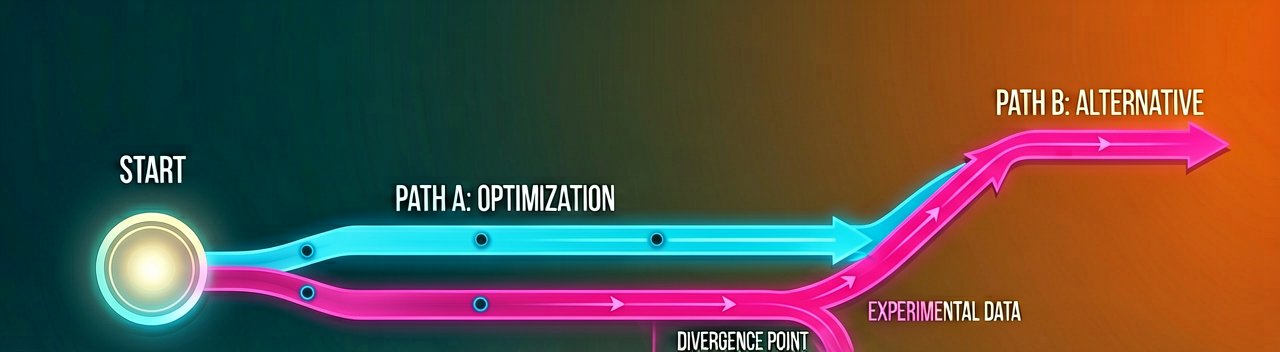
Recommendations analyze production traces and evaluation outputs to optimize your system prompt or tool descriptions for the evaluator you specify. Batch evaluation helps test the recommendation against a pre-defined test dataset and reports aggregate scores, catching regressions on cases you know matter. When hand-authored scenarios aren't enough, you can also simulate a dataset using an LLM-backed actor to play the role of an end user. A/B testing runs a controlled comparison between versions of an agent through AgentCore Gateway, splitting live production traffic at the percentage you configure and reporting results with confidence intervals and statistical significance.
Here is how the loop runs for the model upgrade scenario. End-to-end traceability in AgentCore captures every model call, tool invocation, and reasoning step as OpenTelemetry-compatible traces managed using AgentCore Observability. Evaluations score those traces automatically across dimensions like goal success rate, tool selection accuracy, helpfulness, and safety, using built-in evaluators, ground-truth comparisons, or custom LLM-as-judge scoring.
Generate a recommendation. Point the Recommendations API at the CloudWatch Log group where your agent writes traces. Pick the reward signal as the evaluator you want to optimize for, either a built-in evaluator from AgentCore or a custom evaluator you've built, and choose what to optimize: the system prompt or the tool descriptions. AgentCore reflects on the traces, considering the provided reward signal, and generates a recommendation aimed at improving the performance on that reward signal. For tool description recommendations, it only sharpens the tool description without touching the tool implementation. The service proposes, and you decide what to take forward into the validation steps.
Package the change as a configuration bundle. Configurations ship as bundles, which are immutable, versioned snapshots of your agent's configuration keyed by runtime ARN: model ID, system prompt, tool descriptions. Your agent reads its active configuration dynamically at runtime through the AgentCore SDK, so swapping a prompt or a model is a configuration change, not a code change. Create one bundle for your current configuration and another for the recommendation. Bundles are optional. For changes that include code, deploy to a separate runtime endpoint instead.

Validate offline: batch evaluation. Run your agent against a curated data set using the new bundle, then evaluate the resulting sessions in batch and compare aggregate scores to your baseline. This catches regressions on use cases you have already defined. Teams typically wire batch evaluation into their CI/CD pipelines so no configuration change reaches production without passing their known-good cases.
Validate against live traffic: A/B testing. Configure AgentCore Gateway to split live production traffic between two variants, with the current version as the control and the candidate as the treatment. Variants can be different bundle versions on the same runtime for configuration-only changes, or different gateway targets pointing to separate runtime endpoints for changes that include code. Online evaluation scores every session with your specified evaluator.
Documentation from AWS Bedrock AgentCore confirms the feature is in public preview with no separate charge. You pay only for the underlying AgentCore capabilities you use. However, there's a notable limitation: AgentCore Optimization does not support AWS CloudTrail. API calls to these features do not appear in your CloudTrail event history or configured trails; support will be added shortly. Other AWS service events in your account are not affected. Do not use these features for workloads that require a CloudTrail audit trail until support is added.
Yoshiharu Okuda, Head of Generative AI Business Strategy Department at NTT DATA, provided an early customer perspective. "Continuously evaluating and improving agents is essential for driving data-driven value creation. Processes that traditionally required weeks of manual prompt tuning have evolved into rapid, repeatable cycles through the use of AgentCore. By deriving improvement recommendations from production trace data and validating their impact through A/B testing, organizations can optimize performance while ensuring accuracy and effectiveness. This approach enables continuous, highly efficient improvement at scale."
Every recommendation requires your approval before it ships. The physical reality of using this system means clicking through the AWS Console to review proposed prompt changes, watching batch evaluation scores populate in real-time, and configuring traffic splits through the Gateway interface. It's not magic—it's still work, just less of the tedious kind.
According to the AWS What's New announcement, you can use optimization capabilities in all AWS Regions where AgentCore Evaluations is available. The feature completes the performance improvement cycle for agents. Agents don't just run, they get better, on your terms.
Whether organizations actually adopt this workflow remains the real question. Many teams have already invested in custom evaluation pipelines and may not want to migrate to AWS's proprietary tooling. The preview status means features and APIs may change before general availability. For now, it's a compelling option for teams already deep in the Bedrock ecosystem, but the lock-in implications are worth considering before committing production workloads.
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments