NVIDIA Unveils Nemotron 3 Nano Omni Multimodal AI Model
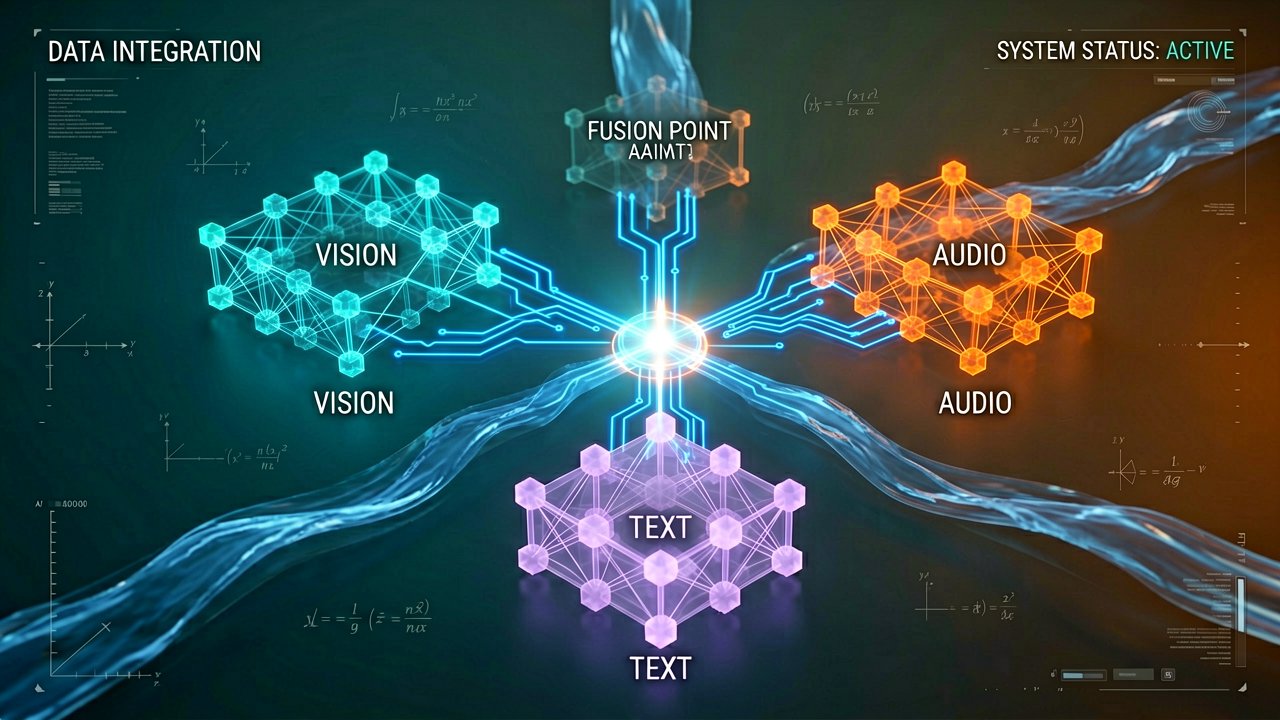
On April 28, NVIDIA released Nemotron 3 Nano Omni, an open multimodal model that processes video, audio, images, and text within a single system. The announcement came through the company's official technical channels, positioning the model as a replacement for the three separate inference stacks—vision, speech, and language—that most agentic workflows currently require.
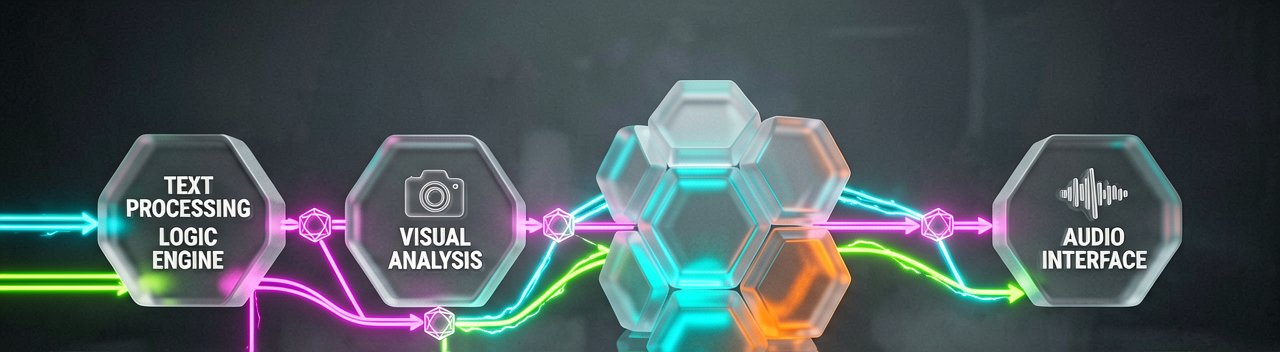
The core problem is straightforward. Today's AI agents juggle separate models for different tasks. A customer support agent analyzing a screen recording, checking call audio, and reviewing data logs would typically need three inference passes across three different models. That fragments context, increases latency, and adds cost. (It's also annoying to debug when one model hallucinates and the others don't catch it.)
Nemotron 3 Nano Omni combines vision and audio encoders within a single 30B-A3B hybrid mixture-of-experts architecture. One model handles everything—text, images, audio, video, documents, charts, and graphical interfaces—with a 256K context window. The result: 9x higher throughput than other open omni-modal models with the same interactivity, according to NVIDIA's official blog post.
Physical interaction matters here. When an agent navigates a graphical interface, it needs to process screen recordings at native 1920×1080 resolution without dropping frames or losing temporal context. The model uses 3D convolutions to capture motion between frames, and an inference-time Efficient Video Sampling layer compresses high-density visual tokens into a concise set the LLM can process without overwhelming its context window.
Three primary use cases define the deployment strategy. Computer use agents power the perception loop for systems navigating graphical user interfaces. H Company has integrated Nano Omni into its computer usage agent, processing screen recordings at full HD resolution. In preliminary evaluations on the OSWorld benchmark, the integration showed significant improvements in navigating complex GUIs.
Document intelligence interprets documents, charts, tables, screenshots, and mixed-media inputs. This is critical for enterprise analytics and regulatory compliance workflows, where agents need to reason across visual structure and text content coherently. Audio-video understanding maintains context across what was said, shown, and documented—useful for customer service, research, and monitoring applications that currently require separate models to handle each modality.
The model tops six leaderboards for complex document intelligence, video understanding, and audio reasoning. It leads on MMlongbench-Doc, OCRBenchV2, WorldSense, DailyOmni, and VoiceBench. Beyond accuracy, MediaPerf—an open industry benchmark evaluating video understanding models on real media data—shows Nemotron 3 Nano Omni achieving the highest throughput across every task and the lowest inference cost for video-level tagging, per NVIDIA's developer documentation.
Open weights, datasets, and training techniques accompany the release. Developers can customize the model using NVIDIA NeMo for domain-specific use cases. The model deploys consistently from edge devices like NVIDIA Jetson hardware and DGX Spark workstations to data center and cloud environments. It's available now via Hugging Face, OpenRouter, build.nvidia.com, and more than 25 partner platforms.

Companies already adopting Nemotron 3 Nano Omni include Aible, Applied Scientific Intelligence, Eka Care, Foxconn, Palantir, and Pyler. Dell Technologies, DocuSign, Infosys, Oracle, and Zefr are evaluating the model. Eka Care, an Indian healthcare platform, is using Nano Omni for multimodal patient care workflows at an India-scale deployment.
The model extends the Nemotron 3 family, which has seen over 50 million downloads in the past year. The family includes Nano (efficient), Super (high-frequency execution), and Ultra (complex planning) variants. In agentic systems, Nano Omni handles perception while other Nemotron models or proprietary systems handle execution and planning—a modular approach that lets developers mix open and closed models based on their requirements.
Technical implementation supports hardware-aware optimized inference across multiple GPU architectures, including NVIDIA Ampere, Hopper, and Blackwell GPU families. It supports FP8 and NVFP4 quantization, efficient video sampling, and NVIDIA-optimized kernels to deliver predictable, low-latency inference. On Blackwell GPUs with NVFP4 quantization, the model achieves the highest throughput among open omnimodal models for enterprise-grade workloads.
Whether enterprises actually migrate away from their existing fragmented stacks remains the real question. The efficiency gains are measurable, but integration costs and workflow changes aren't free. The model is available now, but adoption will depend on whether developers find the unified architecture worth the migration effort.
Artūras Malašauskas is an AI Systems Integrator with 20+ years of production-grade web engineering experience. He has designed, shipped, and scaled enterprise Python/PHP systems for logistics, SaaS, and public-sector clients. For the past year, he has focused exclusively on AI integrations: deploying open-source LLMs, building generative media pipelines (image, audio, video), and engineering multi-agent workflows for real production environments. His standard: reproducibility, security, cost-efficient inference—no vaporware. He documents and evaluates emerging AI tooling, separating verified capabilities from marketing noise. Technical editor at: muza-ai.eu, ai-verslas.lt, ai-naujinos.lt Connect on LinkedIn
Comments